Preface
Editor暂时还没有任何关于光照,甚至是texture map的相关实现。本篇文章将介绍纹理方面的高效存储及Editor GBuffer的布局,及PBR shading的初步测试。
容器格式
不看轮子和各种私有格式的话,常用的主要有DDS和最近的KTX2。
KTX
虽然工具链很成熟,在新版Vulkan Tutorial中也被绝赞推荐:但由于全平台支持,直接使用的话由于各种编码产生的依赖会多的离谱(--depth=1 clone大小约莫~1GB!),因此这里没有选择。
DDS
最后挑的还是DDS,因为容器本身很简单:"DXT " + DDS_HEADER + DDS_HEADER_DXT10后即为对应编码下linear tiled数据,可以分成layer/mip直接上传 GPU。至于为什么不应该(Linear Tiling)整个上传(或者,GPU上的纹理到存储方式为什么是硬件相关的),请参考 Image Copies - Vulkan Documentation。
实现上主要是读文档——部分结构直接从DirectXTex - DDS.h copy过来了。用DDS有一个好处就是能被第三方工具直接打开,同时,Editor序列化纹理也将如此存储。
纹理格式
运行时解码成全精度,原始的R8G8B8A8UNORM等格式存储诚然是…一种选择。不过记得之前和某个Unity游戏打交道见过其在资产里直接存了原始RGB565(RGB 16 bit)量化格式的纹理做NPR 效果。但是至于为什么要用这种格式,搜了半天也没找到个结果(汗)
纹理压缩,可能除了UI带alpha材质的极端情况外,基本是必做的事情。GPU硬件解码其支持的格式开销是几乎不存在的——参考 Unity 给出的材质格式推荐:
DXTc/BCn/ETC
桌面端,支持最广泛的包括各种BCn/Block Compression [n]压缩 - 参见 Understanding BCn Texture Compression Formats - Nathan Reed;同时,BC1,BC2,BC3 也被微软叫成 DXT1, DXT3, DXT5,这里提及以防混淆。最后,在近十年支持DX11级别的桌面硬件中,无脑使用
BC6(H),BC7基本没问题。移动端,ETC曾是主流:Unity的crunch就提供第一方DTXc/BCn和ETC的支持。现在的移动硬件一概支持更优秀且开源的ASTC:Unity自己也在使用ARM官方的开源astc-codec处理编码。但需要注意的是,桌面硬件上对astc的支持几乎不存在。这点也可以自己利用Vulkan Caps Viewer检查:

Basis Universal
可见硬件上——上述压缩编码在桌面/移动端的支持是没有交集的。但是纹理压缩做的工作本身会有很多重叠(如 DCT编码等等)—— basisu 即可高效地存储一种统一编码格式,并在运行时非常快速地转换到目标平台使用编码上传GPU。
额外的,basisu也自带一层哈夫曼编码 - 这是在所有block处理完之后全局进行的,因此整体压缩率在相同平均bpp下也会比单纯的BCn等编码一般地会更高。
BC7
最后在GPU和文件本身存储上还是采用了BC7 - Editor内置了来自crunch作者Richard Geldreich 的 bc7enc 实现。这样也方便直接读取并直接转码JPG/PNG存储的glTF模型纹理。
和之前网格一样,优化(转码)/烘焙部分是可以离线的。以下是结合mip生成以后产生的DDS在tacentview预览效果:具体实现细节太多,姑且就不贴在这里了。有兴趣可以点这里查看。

GBuffer
我们实现的是延后(Deferred)渲染。现在暂不考虑探索移动端(和果子M芯片)的TBDR (Tile Based Deferred Rendering),在用的IMR (Immediate Mode Rendering) 模式还是需要几个Pass的。
Task/Mesh部分在前面已经讲得很详细,这里不再多说。接下来发生的事情,基本在 Pixel/Fragment 和 Compute 里进行。
GBuffer 布局

目前的最终目标是能完整表现glTF的Metallic-Roughness模型。除了Base Color/底色及法线贴图外,我们还有两个Metal/Rough参数是必须表现的,图中还有自发光材质。最后,可选的occlusion/预烘焙AO在此暂时不考虑。
结合上一篇介绍的一些packing和切空间压缩奇技淫巧,我们的GBuffer可以整理得很简洁,参见下表。所有RT格式皆为R8G8B8A8Unorm
| Target | R | G | B | A |
|---|---|---|---|---|
| RT0 | BaseColor R [8] | BaseColor G [8] | BaseColor B [8] | Material ID [7] + TBN手性[1] |
| RT1 | Normal 投影 X [8] | Normal 投影 Y [8] | Tangent 夹角 [8] | Metallic [8] |
| RT2 | Emissive R [8] | Emissive G [8] | Emissive B [8] | Roughness [8] |
BaseColor, Emissive 直接存储,各占一对RGB通道。
注意:glTF的BaseColor存储于sRGB格式,利用相关硬件材质格式(BC7Srgb/RGBA8Srgb)可以避免shader中额外转换而直接读取解码后线性色彩数据。
Tangent Frame是完整保留的,且只用3字节+1bit(RT1 RGB + RT0 A[1])。后面实现PBR时可以用来实现各向异性效果。
Metallic, Roughness 各占一个通道
此外RT0还有存一个Material ID,不过因为目前glTF只有一种材质模型,所以还用不到。
GBuffer 生成
效果如下,配置好MRT以后:以下为前两个RT的GBuffer表现。鉴于场景内不存在自发光对象则省略RT3。
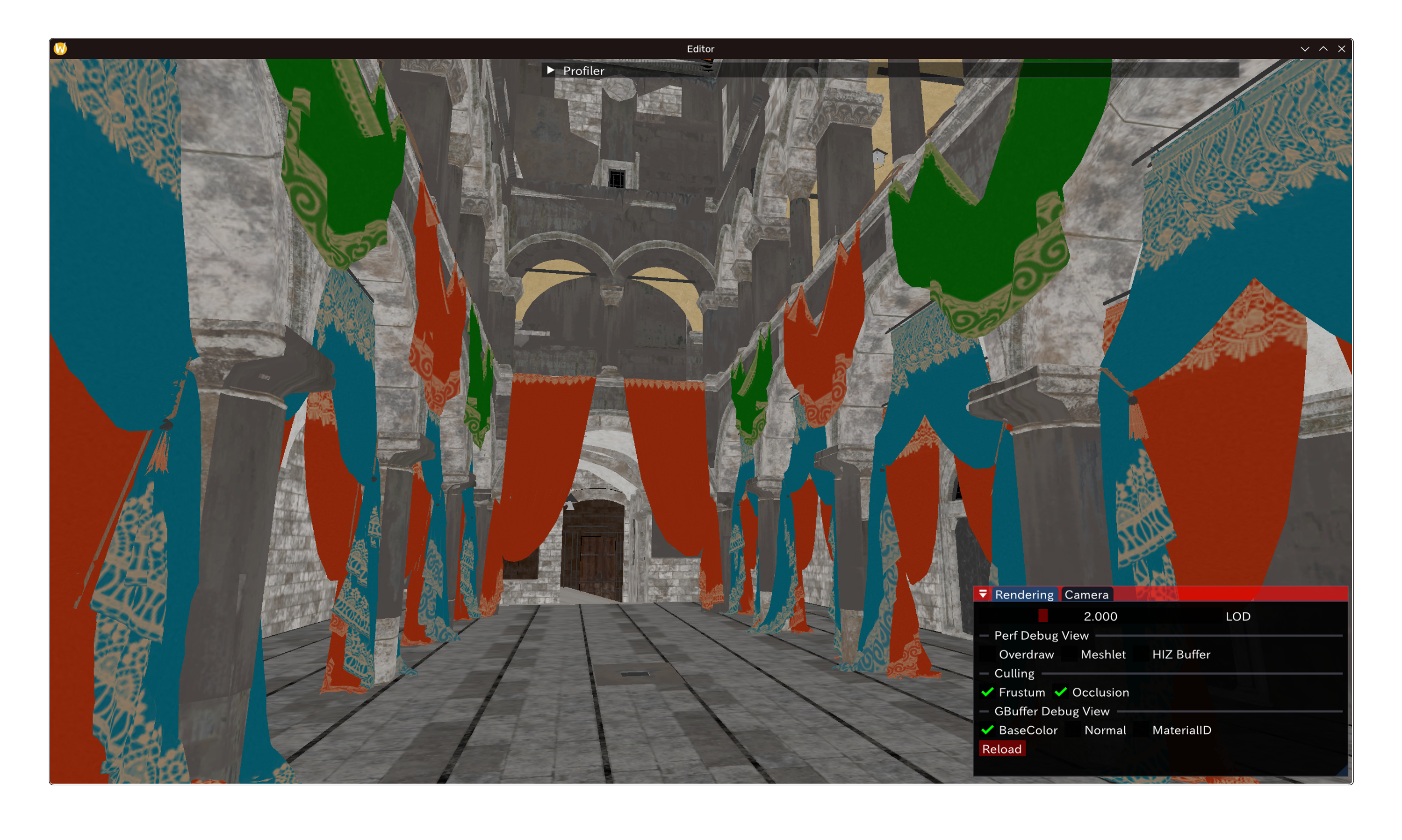
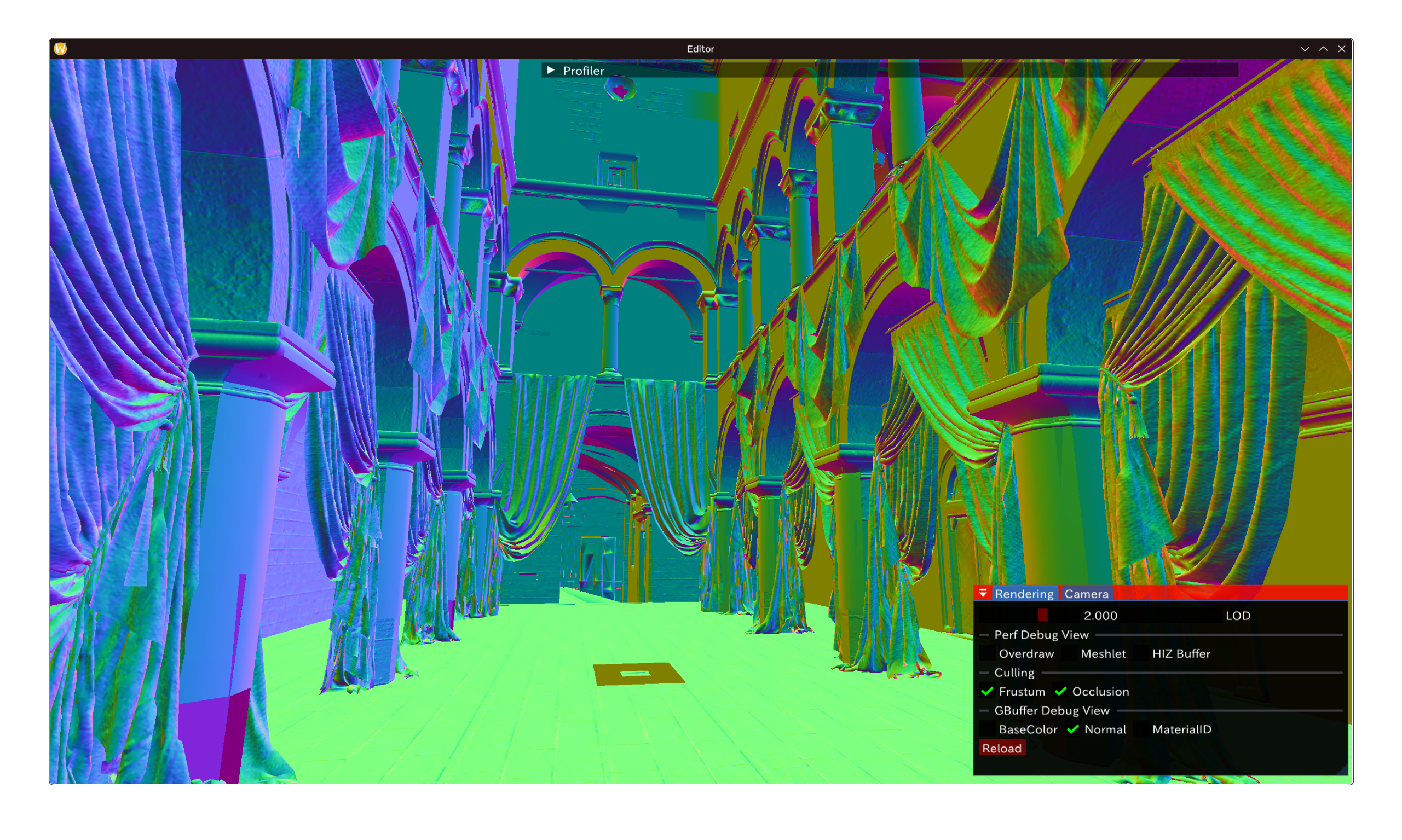
线性 Workflow
正经实现 PBR 光照开始。Physically Based Rendering in Filament 将是我们主要的信息来源。
光照单元
PBR要求我们使用真实的光照单元建模渲染。这里采用Table 10 - Filament中的光照单元和光照类型关系:巧合的,这些单位与glTF扩展KHR_lights_punctual一致。
- 对于平行/太阳光,其单位为$lx$(勒克斯,lux),或$\frac{lm}{m^2}$(每平方米流明)。
- 点光源(包括聚光灯),其单位为$lm$(流明)。
附注: Blender中的GLTF导出会将Blender内光源单位(皆为$W$)做转换,过程即为乘以$683 \frac{lm}{W}$。数字来源请参考前链接。
线性Workflow
SDR仅仅只有$[0,1]$的空间是远远不够建模上述真实的光照单位的。(参考 Table 12 - Filament:可测量到太阳的直射可达$100000 lux$)
HDR渲染不一定蕴含PBR,但反过来是一定的。同时,在线性空间渲染也需要更高精度的framebuffer格式——这里用了B10G11R11。
最后,不论是输出到SDR还是HDR显示器,从线性空间出发的曝光,Tonemapping都是必要的。接下来介绍这两部分内容。
PBR 相机
参考来自以下来源:
- Automatic Exposure Using a Luminance Histogram 及 Tonemapping - Bruno Opsenica
- Automatic Exposure - Krzysztof Narkowicz
- ACES Filmic Tone Mapping Curve - Krzysztof Narkowicz
- 8.1 Physically based camera - Filament
EV100
曝光控制并不会直接从绝对辉度进行,一般由$EV$定义。摘自 EV与照明条件的关系 - 维基百科: $$ \mathrm {EV} =\log _{2}{\frac {LS}{K}} $$
其中$L$为场景平均辉度(average luminance/nit),$S$为ISO指数,$K$为校准指数:一般为$12.5$。代入ISO100及这个值,我们得到$EV_{100}$的定义: $$ EV_{100} = log_2{L\frac{100}{12.5}} $$ EV是一个控制量。对于饱和相机传感器的辐照度$L_{max}$,Moving Frostbite to Physically based rendering V3 及 8.1 Physically based camera - Filament 都给出了以下式子: $$ L_{max} = 2^{EV_{100}} \frac{78}{q \cdot S} $$ 代入常用$q=0.65$与$ISO=100$简化为: $$ L_{max} = 2^{EV_{100}} \times 1.2 = {L\frac{100}{12.5}} \times 1.2 = 9.6 \times L $$ 曝光值$H$的定义为$H=\frac{1}{L_{max}}$ - 最后我们得到将场景辉度归一的完整式子,非常简单: $$ L’ = \frac{L_{pix}}{9.6 \times L} $$
测光
Tonemapping需要知道场景辉度情况——我们想要的是场景平均辉度。朴素的,可以直接对最终lighting buffer进行mip chain生成:字面地求平均后取其最后$1\times1$ mip值的辉度值。不过问题也很明显。摘自Automatic Exposure - Krzysztof Narkowicz:当场景大部份很暗或存在少数极亮光源时,整体平均值会受到很大影响:相机对着的主体可能并看不清楚。
利用直方图则可以忽略这些极值。实现上如下:我们将场景光照映射到一定曝光范围(通过globalParams.camMinEV, globalParams.camMaxEV指定)后去做binning,最后丢掉极值情况后加权取和得到场景平均辉度。完整实现如下:
#include "ICommon.slang"
uniform UBO globalParams;
Texture2D<float4> lighting;
RWStructuredBuffer<Atomic<uint>> bins; // 64 bins. Don't forget to clear.
groupshared Atomic<uint> binGS[64];
[shader("compute")]
[numthreads(8, 8, 1)]
void main(uint2 tid: SV_DispatchThreadID, uint gid : SV_GroupIndex) {
binGS[gid].store(0u);
GroupMemoryBarrierWithGroupSync();
float4 value = 0u;
if (tid.x < globalParams.fbWidth && tid.y < globalParams.fbHeight)
value = lighting.Load(int3(tid.x,tid.y,0));
float luma = dot(value.xyz, float3(0.2126, 0.7152, 0.0722));
float EV = log2(luma + EPS);
int bin = clamp((int)floor(saturate((EV - globalParams.camMinEV) / (globalParams.camMaxEV - globalParams.camMinEV)) * 64.0),0, 63);
binGS[bin].add(1);
GroupMemoryBarrierWithGroupSync();
bins[gid].add(binGS[gid].load());
}
加权平均部分沿用了之前wave intrinsic的求和trick,不再多说。实现如下,注意只保留了$[2,48]$的bin,摈弃过明/暗样本:这里的上下界选择比较随意。
#include "ICommon.slang"
uniform UBO globalParams;
StructuredBuffer<uint> bins;
RWStructuredBuffer<float> output; // Final scene avg. luminance
groupshared Atomic<uint> countGS, weightGS;
[shader("compute")]
[numthreads(64, 1, 1)]
void reduce(uint gid : SV_GroupIndex, uint groupID : SV_GroupID) {
countGS.store(0u); weightGS.store(0u);
GroupMemoryBarrierWithGroupSync();
// Drop extremities
bool keep = (gid >= 2 && gid <= 48);
uint count = bins[gid] * keep;
uint weighted = count * gid;
uint countWave = WaveActiveSum(count);
uint weightWave = WaveActiveSum(weighted);
if (WaveIsFirstLane()){
countGS.add(countWave);
weightGS.add(weightWave);
}
GroupMemoryBarrierWithGroupSync();
if (gid == 0) {
// sum = Num_i * (EV_i - min)/(max-min)*64
uint countAll = countGS.load(); // No. samples in range
uint weightAll = weightGS.load(); // Weighted samples sum
float meanEV = ((float)weightAll / countAll) / 64.0f * (globalParams.camMaxEV - globalParams.camMinEV) + globalParams.camMinEV;
float meanLuma = exp2(meanEV);
float meanLumaPrev = output[0];
meanLumaPrev = isnan(meanLumaPrev) ? meanLuma : meanLumaPrev;
float lumaAdapted = meanLumaPrev + (meanLuma - meanLumaPrev) * clamp(globalParams.camAdaptCoeff,0.0f,1.0f);
output[0] = lumaAdapted;
}
}
其中camAdaptCoeff来自 8.1.4 Automatic exposure,在CPU侧计算。式子为:
$$
L_{avg} = L_{avg} + (L - L_{avg}) \times (1 - e^{-\Delta t \cdot \tau})
$$
借此可以产生“自适应”效果,同时规避场景变化可能带来辉度突变。
Tonemapping 曲线
归一化的$L’$并不一定回落在SDR的$[0,1]$区间。此外,对最终暗部、高光表现“修图”也是一个基操:这点常常用某种曲线完成。
业内用的最多的或许是ACES/Filmic:用户包括Unity, UE 及 Blender 等等。Blender在4.0以后开始默认使用AgX替代ACES曲线,原因出于(应用原文):
This view transform provides better color handling in over-exposed areas compared to Filmic. In particular bright colors go towards white, similar to real cameras. Technical details and image comparisons can be found in PR#106355.
…更写实?不清楚怎么回事。不过实现上,官方提供的仅有 ACES:OCIO, AgX:OCIO profile:直接集成有些小题大做。此外,真正完整的曲线计算相当,相当复杂:参考Unreal ACES 和 ACES Overview - Wikipedia。
一个偷懒但有效的方法即为构造LUT查表调色Tonemap之前的线性空间(如用Linear Rec 709表示),或者借更少数据点拟合曲线。以下为 ACES Filmic Tone Mapping Curve - Krzysztof Narkowicz 给出的ACES fit:
float3 ACESFilm(float3 x)
{
float a = 2.51f;
float b = 0.03f;
float c = 2.43f;
float d = 0.59f;
float e = 0.14f;
return saturate((x*(a*x+b))/(x*(c*x+d)+e));
}
还有更多Fit参见Tonemap operators incl. reinhard - Shadertoy by bruop;另外,Shadertoy上还有不少Agx的实时实现,可供参考。
显示器空间转换 (EOTF)
到目前为止,我们的一切操作还都是在线性空间中完成的。对于SDR/HDR显示设备,信号还需要转换到他们能接受的格式:这个操作也也叫 EOTF(Electro-Optical Transfer Function)。参见 Displays and Views - Blender Manual
因为没有正经HDR屏幕 简单起见,我们在tonemapper最后做一次linear->gamma/sRGB的转换即可。sRGB到显示器的过程不属于我们需要处理的范畴。
最后,完整的Linear场景SDR呈现流程如下(节选),采用了最简单的ACES Fit和Gamma转换。
float Lavg = sceneLuma.Load(0u);
float3 Lpix = lighting.Load(coord).xyz;
// Exposure
float3 L = Lpix/(Lavg * 9.6f);
// ACES
L = ACESFilm(L);
// Inverse Gamma EOTF
L = pow(L, 1.0f/2.2f);
return float4(L, 1.0f);
原理化 BRDF
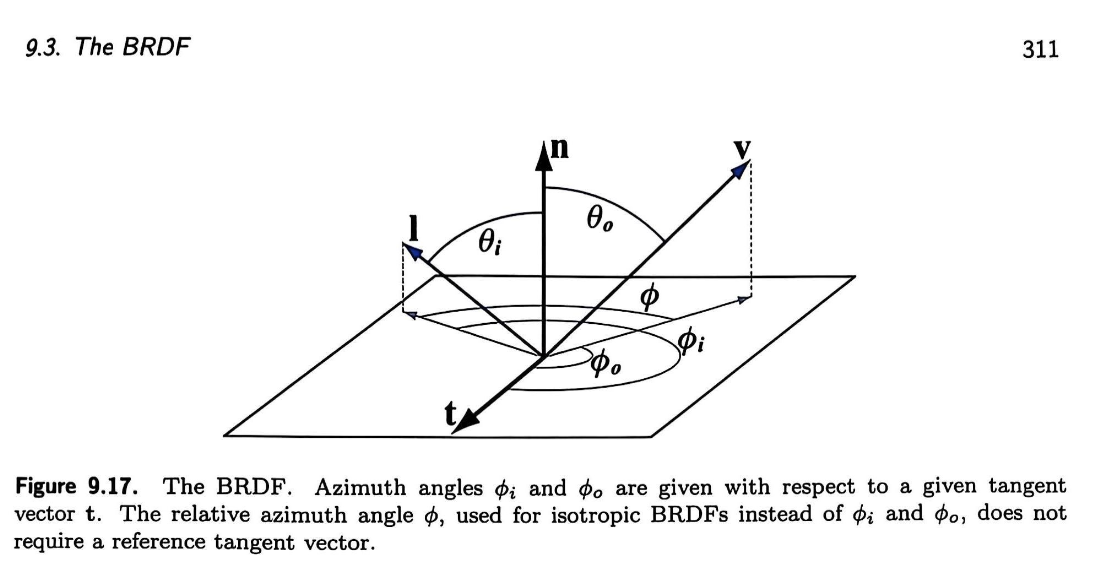
参考 4.1 Standard model - 读者请自行完成相关阅读,这里将不在原理方面过多阐述。图源RTR4,供向量名参考。
GGX + Lambert
BRDF eval这里不讲(见下一篇)。接下来的实现部分也仅供参考:所用的lobe一致,但这不是我们最后使用的写法。
glTF Metal-Rough 模型
Spec的要求(Core)是如下 - 仅包含baseColor, metallic, roughness层。不过 其他的材质层(如Clearcoat)也基本有各种拓展加入;这些以后再看。

注意,glTF 定义其 specular_brdf 为 $VD$ - $F$反射值在后面参与。其中,fresnel_mix 的实现如下,参考B.2.2. Dielectrics
float3 fresnel_mix(float cosAngle, float ior, float3 base, float3 layer) {
float F0 = ((1-ior)/(1+ior))^2;
float3 F = F_Schlick(cosAngle, float3(F0));
return lerp(base, layer, F)
}
注: fresnel_mix可以直觉地认为:入射角靠近切平面时,base层的光照多被反射,看得到的为之下的layer层。不过多层材质的真正叠加是很复杂的:考虑多层之间也会有交互。这里,利用Fresnel做线性组合的方案是一种简化:Autodesk Standard Surface - 4.3 Layering Model 及 OpenPBR 白皮书 中也有提及。更早可考证的来源是[Crash Course in BRDF Implementation - Jakub Boksansky’s Blog](https://boksajak.github.io/files/CrashCourseBRDF.pdf),在Ray Tracing Gem 2 Ch. 14有引用。
最后,官方上面采用$IOR=1.5$,代入即$F0=0.04$。综上,最后该模型完整的实现如下。$D,V$计算省略。
...
float3 v = normalize(eye - p);
float3 l = -globalParams.sunDirection;
float3 h = normalize(v + l);
float NoH = saturate(dot(n,h));
float VoH = saturate(dot(v,h));
float ToV = saturate(dot(t,v));
float BoV = saturate(dot(b,v));
float ToL = saturate(dot(t,l));
float BoL = saturate(dot(b,l));
float NoV = abs(dot(n,v)) + EPS;
float NoL = saturate(dot(n,l));
float3 lighting = float3(NoL) * globalParams.sunIntensity + globalParams.ambientColor;
// Diffuse
float3 Fd = baseColor / PI;
// Specular
float anisotropy = material.anisotropy;
roughness = roughness * roughness;
float at = max(roughness * (1.0 + anisotropy), 0.001);
float ab = max(roughness * (1.0 - anisotropy), 0.001);
float D = D_GGX_Anisotropic(NoH, h, t, b, at, ab);
float V = V_SmithGGXCorrelated_Anisotropic(at, ab, ToV, BoV, ToL, BoL, NoV, NoL);
// glTF spec calls D*V the specular BRDF, F is introduced later.
float Fs = D * V;
// https://registry.khronos.org/glTF/specs/2.0/glTF-2.0.html#metal-brdf-and-dielectric-brdf
float3 metalBRDF = Fs * F_Schlick(VoH, baseColor);
float3 dielectricBRDF = lerp(Fd, Fs, F_Schlick(VoH, float3(0.04)));
float3 material = lerp(dielectricBRDF, metalBRDF, metallic) * lighting;
验证
以下为glTF-Sample-Assets - FlightHelmet场景在Editor和Blender 5.0 EEVEE中渲染结果对比。
注意: 在这里有做出以下限制:
- 二者都仅有单个直接平行光源
- 没有间接照明或环境光/AO
- 没有任何形式的阴影实现
此外,相机及光照各参数(角度,功率/lux)也已保证一致,Blender中使用的tonemapper也为ACES1.3——至此可以认为我们的glTF材质模型是基本正确的。
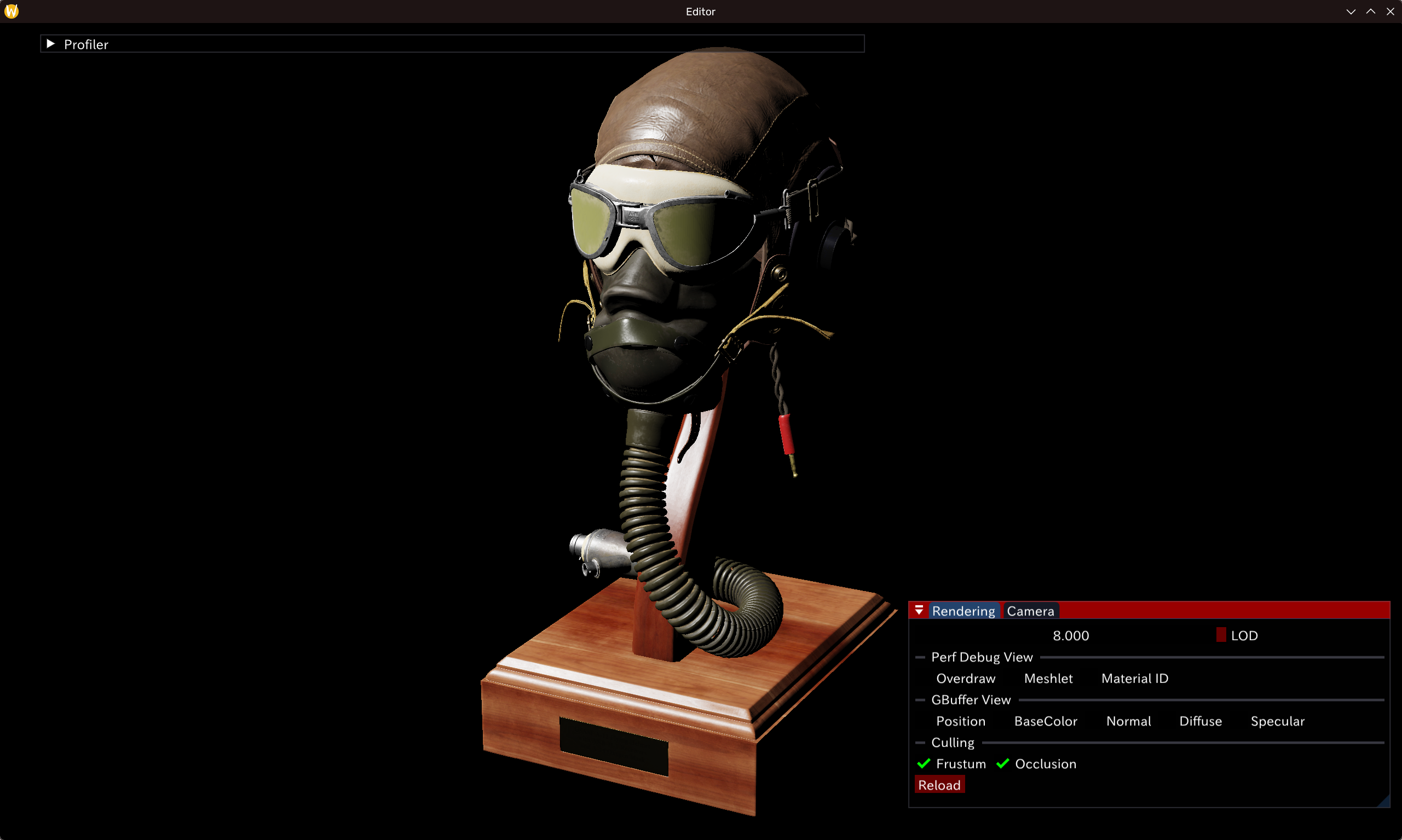

阴影
光线追踪初步
现在即使集显及移动端也支持硬件光线追踪加速:我的本子也是如此。此外,Inline Raytacing的存在也让集成RT功能变得相当可观:比较反直觉地,利用Inline RT硬件做阴影会比传统的shadowmap简单不少(不需要额外shadow pass等等)。
且对于(硬)阴影而言,RT结果是ground truth:不会存在各种shadowmap实现中可能存在的精度问题。接下来我们利用inline RT和Foundation最近添加的RT相关RHI更进我们的GPUScene。
GPU Scene API
目前,我们做一个非常方便偷懒的限制:BLAS加速结果构建完后不会更新。GPUScene中提供了这样的API:
void BuildBLAS(ImmediateContext* ctx, Span<const GSMesh> meshes, Span<uint32_t> outBLASIndices);
void BuildTLAS(RHICommandList* cmd, Span<const GSInstance> instances, Span<const uint32_t> blasIndices, bool update = false);
- BLAS/Submesh 提交可以分批进行,添加新BLAS会保留已有AS
- TLAS有且仅有一个,每一帧都有更新的操作。
- 最后的到的TLAS可以绑定到shader管线直接inline,或者走SBT/Shader Binding Table利用。本篇只用前者。
Shader 反射
首先,加入最小化inline RT实现硬阴影的Slang Shader仅需添加以下内容:
RaytracingAccelerationStructure AS;
bool shadow(float3 p, float3 l)
{
RayDesc ray;
ray.Origin = p;
ray.Direction = l;
ray.TMin = 1e-2;
ray.TMax = 1e2;
RayQuery<RAY_FLAG_ACCEPT_FIRST_HIT_AND_END_SEARCH> q;
q.TraceRayInline(AS, RAY_FLAG_ACCEPT_FIRST_HIT_AND_END_SEARCH, 0xFF, ray);
while (q.Proceed()){
// Not alpha tested. A hit is a shadow.
q.CommitNonOpaqueTriangleHit();
break;
}
bool hit = q.CommittedStatus() == COMMITTED_TRIANGLE_HIT;
return hit;
}
...
float3 lighting = float3(NoL) * globalParams.sunIntensity + globalParams.ambientColor;
lighting *= shadow(p, l);
Renderer建图也加了对应的绑定API,SRV/ReadOnly和Write/AS Build/Update声明足矣。
r->BindAcceleartionStructureSRV(self, TLAS, RHIPipelineStageBits::ComputeShader, "AS");
...
renderer->CreatePass(
"TLAS Update", RHIDeviceQueueType::Compute, 0u,
[=](PassHandle self, Renderer* r)
{
r->BindAccelerationStructureWrite(self, TLAS);
},
[=](PassHandle, Renderer* r, RHICommandList* cmd)
{
gpu->BuildTLAS(cmd, *scene.gsInstances, *scene.gsBLASes, true);
}
);
在Vulkan后端,启用VK_KHR_acceleration_structure及VK_KHR_ray_query拓展并开启以下功能则允许这里的Ray Query被运行。以下是目前用到的extension chain:
vk::StructureChain<vk::PhysicalDeviceFeatures2, vk::PhysicalDeviceVulkan11Features,
vk::PhysicalDeviceVulkan12Features, vk::PhysicalDeviceVulkan13Features,
vk::PhysicalDeviceExtendedDynamicStateFeaturesEXT,
vk::PhysicalDeviceMeshShaderFeaturesEXT,
vk::PhysicalDeviceAccelerationStructureFeaturesKHR,
vk::PhysicalDeviceRayQueryFeaturesKHR
>
...
{.accelerationStructure = true,}, // vk::PhysicalDeviceAccelerationStructureFeaturesKHR
{.rayQuery = true} // vk::PhysicalDeviceRayQueryFeaturesKHR
};
调试
有点蛋疼。之前Debug一直用的是 RenderDoc,但是人家现在还不支持任何RT功能。这里只能用第一方工具。
但是又因为目前用的RADV驱动:AMD RDP 对其基本没有任何调试功能。部分功能,比如从驱动导出 RGP Profile (MESA_VK_TRACE)是可能的,此外嘛…

驱动切换?
实在哈人。这里暂时换回旧官方带完整调试支持的驱动了。在我的Arch机器上可以这么做:
- 安装
AMDPROVulkan驱动:vulkan-amdgpu-pro - 运行时可以利用 amd-vulkan-prefixes 切换
- RADV:
vk_radv ... - AMDPRO:
vk_pro ...

不过不幸的是,在这里Task Shader - 至少在我的机器上仍然不能正常工作。Linux下会丢设备:用RADV_DEBUG=hang跟日志可以到这里

在Mesh MDI找到了’last trace point’…不过说实话看不懂。

在Win下开启RGP会在这里产生AV - Crash Analysis 抓不到…

PTSD时间 结合之前的实验,看起来这个feature确实没法用在_至少是_我的机器和AMD官方驱动上。
Kill The Task Shader
既然有可能出现这种spec允许但跑不起来的情况:除了希望官方修复(注:Linux AMDPRO驱动已经停止维护)之外,也只能另请高明…Hans-Kristian Arntzen/The Maister 这篇 mesh shader实践中也提到了task shader支持多烂:参考 “Task shader woes” 部分。也许“没有3A在用”也是能出问题的一个理由。
这里,我用了单独的一次CS Dispatch来模拟Task Shader做的事:原来在TS做的Culling放到CS后,整理成连续的meshlet ID列表。实现上和DispatchMesh很像:不过不涉及LDS,并且我们在后面自己dispatch。
这下能跑了。在Linux下也能直接用RDP顺利抓到这里的Profile。
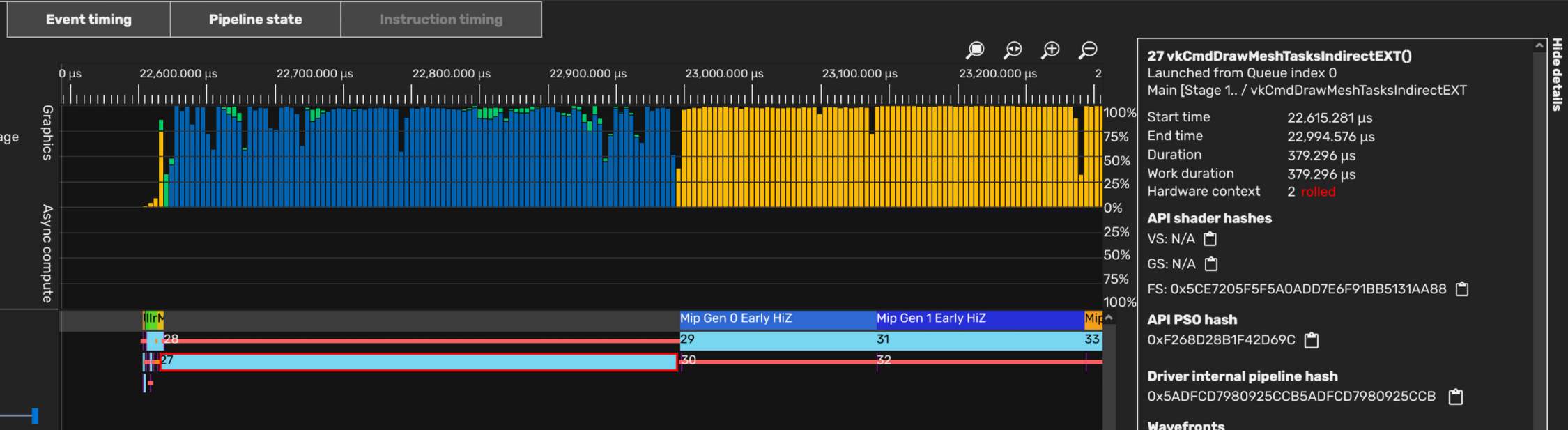
同时,在 RGP 中也能捉到RT场景。

效果
如图:可见这里支架部分的硬阴影效果;注意到右侧TLAS更新是跑的Async Compute(绿色)。
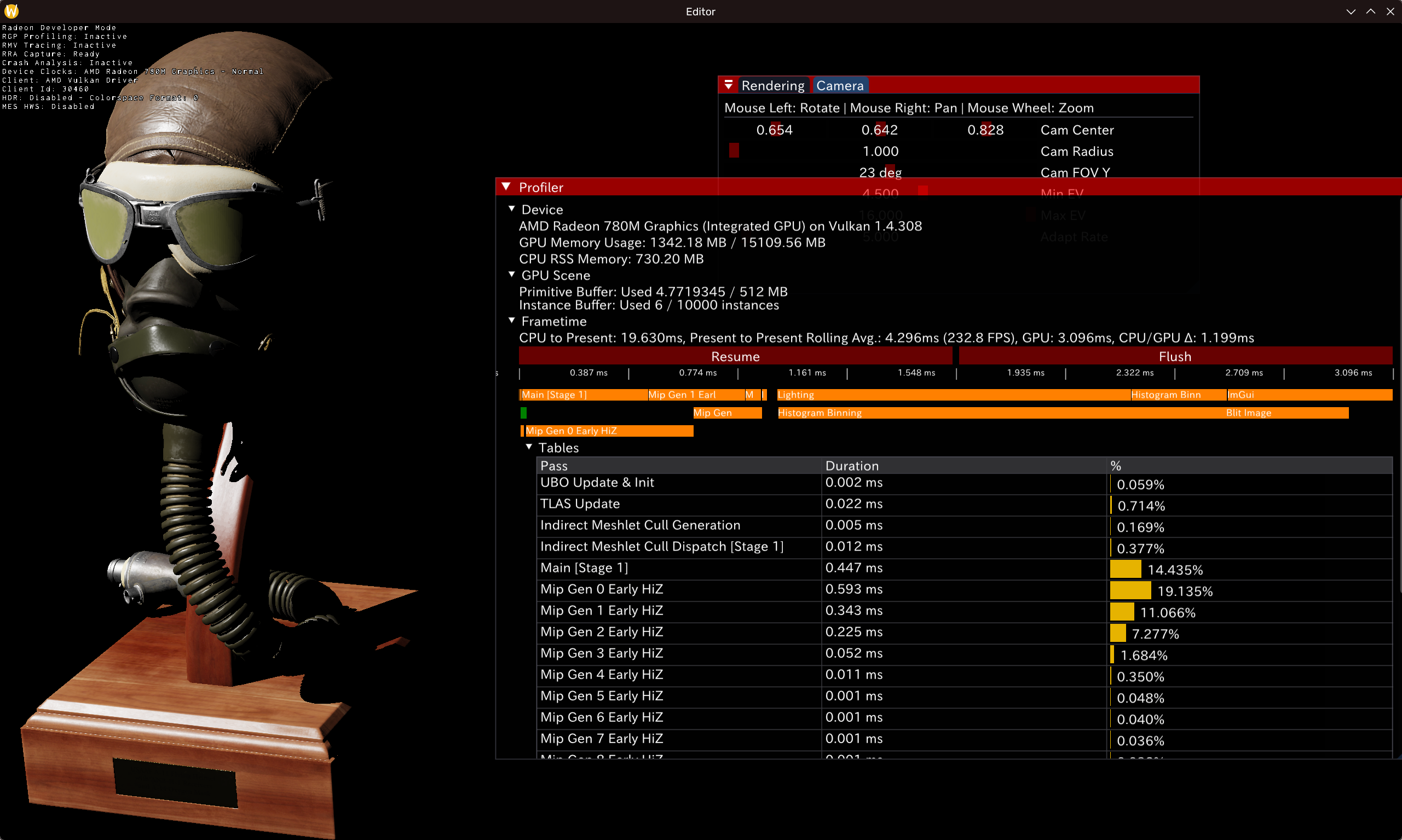
更复杂的场景(glTF Sponza)中效果如下。值得注意的是这里的环境有背景(Ambient)光源,强度为20000Lux。

花絮:FFXSPD 集成
开始下一篇之前想把这个坑填了。同时在SPD Downsample完后方便起见做了一个Mip 0的copy,如下:
[shader("compute")]
[numthreads(256, 1, 1)]
void csMain(uint3 WorkGroupId : SV_GroupID, uint LocalThreadIndex : SV_GroupIndex) {
SpdDownsample(
AU2(WorkGroupId.xy),
AU1(LocalThreadIndex),
AU1(pc.mips),
AU1(pc.numWorkGroups),
AU1(WorkGroupId.z),
AU2(0, 0));
// Needs a copy for MIP 0. We work on 64x64 tiles
if (!pc.sameSrcDst)
{
uint2 tile = WorkGroupId.xy;
uint2 tileOffset = tile * 64;
uint2 threadOffset = uint2(LocalThreadIndex % 16, LocalThreadIndex / 16) * 4;
uint2 pixelCoord = tileOffset + threadOffset;
for (uint y = 0; y < 4; ++y)
for (uint x = 0; x < 4; ++x)
{
uint2 coord = pixelCoord + uint2(x, y);
if (coord.x < pc.extents.x && coord.y < pc.extents.y)
{
float4 value = SpdLoadSourceImage(AF2(coord), AU1(WorkGroupId.z));
imgDst[0][uint3(coord, 0)] = value;
}
}
}
}
不过有些意外,初步集成后的占有率仅在25%左右:
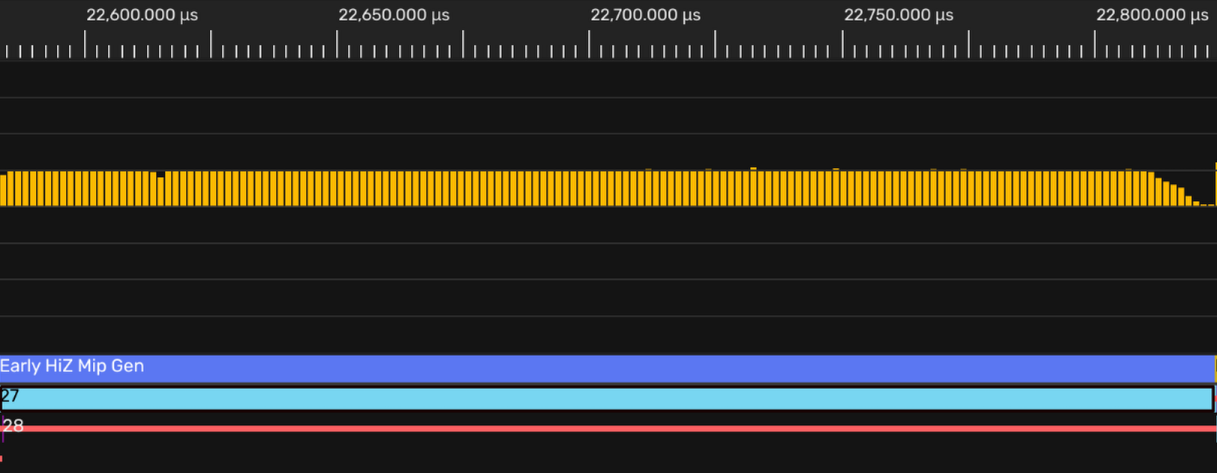
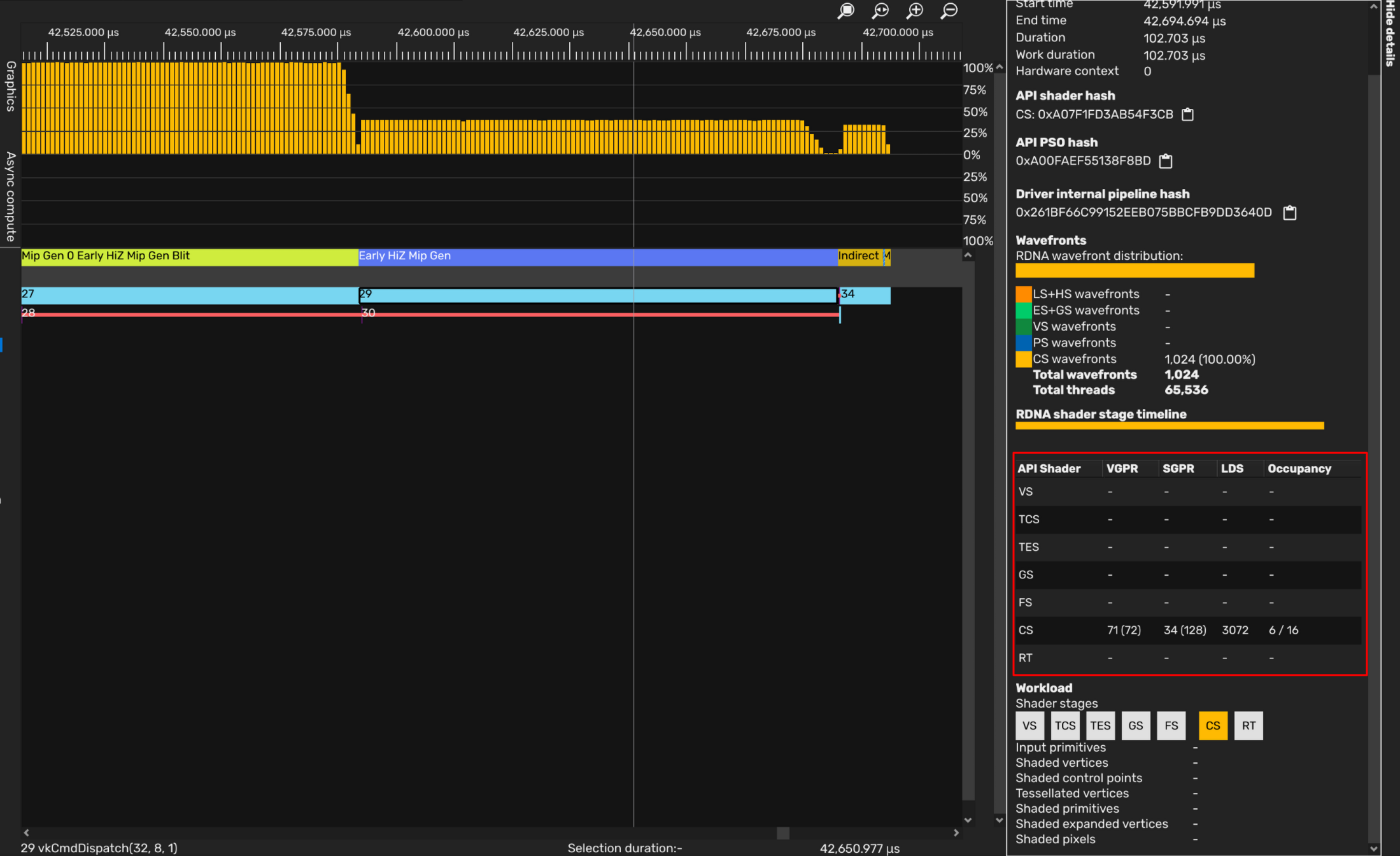
在Pipeline state看得到VGPR使用量相当高(86个!)。Wave64模式下只跑了4个Wave…


不过SPD有支持FP16,同时参考 RDNA Performance Guide - 使用A_HALF选择FP16操作可减轻寄存器压力。同时Copy部分分成另外一次dispatch:可见VGPR使用降低到了71,多跑了2个Wave。
最后,在此copy mip0本身意义并不大:half res的mip chain做剔除够用,而且APU带宽有限,不妨直接省略copy步骤?
最后决定HIZ从half res (mip 1)开始少一步copy。Profiler时序干净了不少——但是性能上和多次dispatch mip chain相比差不多;在APU带宽受限(DDR)且暂时没有能够并行的GPU工作的情况下,看起来SPD优势并不是很明显。
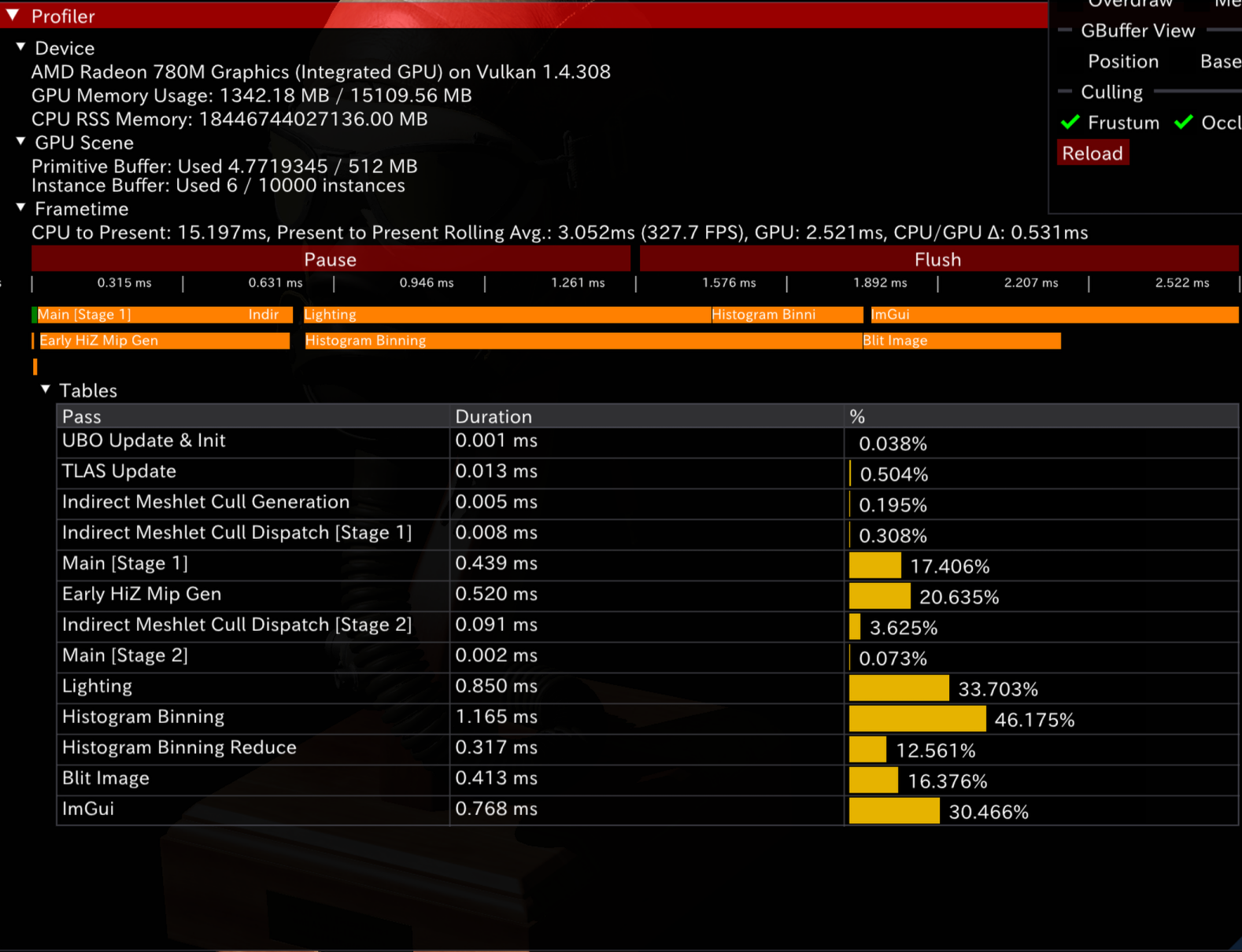
注: 这里(Linux/Windows AMDPRO驱动)的timing相当地不准确——在RADV下时序是整齐的两条(Graphics+Async Compute),而且这里的数据和RDP里对不上。未来若有解决方案会在这里补充。
References
- DDS - Microsoft Docs
- KTX File Format Specification
- KhronosGroup/KTX-Software - GitHub
- Understanding KTX2 - Vulkan Tutorial
- DDS header - Microsoft Docs
- Image Copies - Vulkan Documentation
- DirectXTex/DDS.h at main · microsoft/DirectXTex
- Unity Texture Formats
- Understanding BCn Texture Compression Formats - Nathan Reed
- S3 Texture Compression - Wikipedia
- Unity-Technologies/crunch - GitHub
- ARM-software/astc-encoder - GitHub
- BinomialLLC/basis_universal - GitHub
- .basis File Format and ETC1S Reference Implementation Overview
- Rich Geldreich’s Blog
- richgel999/bc7enc - GitHub
- bluescan/tacentview - GitHub
- Foundation/Editor/Texture.cpp at vulkan · mos9527/Foundation
- Rendering a Scene with Deferred Lighting in C++ - Apple Developer
- glTF 2.0 Specification - Materials
- Physically Based Rendering in Filament
- Physically Based Rendering:From Theory To Implementation
- kanition/pbrtbook (Chinese Translation)
- Real-Time Rendering 4th Edition
- KHR_lights_punctual - glTF Extension
- glTF-Blender-IO/conversion.py
- Automatic Exposure Using a Luminance Histogram - Bruno Opsenica
- Tonemapping - Bruno Opsenica
- Automatic Exposure - Krzysztof Narkowicz
- ACES Filmic Tone Mapping Curve - Krzysztof Narkowicz
- 曝光值#EV与照明条件的关系 - 维基百科
- Light meter#Calibration_constants - Wikipedia
- Moving Frostbite to Physically based rendering V3
- AgX View Transform - Blender PR#106355
- OpenColorIO-Configs - ACES
- sobotka/AgX - OCIO
- Unreal Engine - ACES_v1.3.ush
- Academy Color Encoding System - Wikipedia
- Tonemap operators incl. reinhard - Shadertoy
- Shadertoy search results for “agx”
- Displays and Views - Blender Manual
- glTF 2.0 Specification - Microfacet Surfaces
- wdas/brdf/disney.brdf - GitHub
- KHR_materials_clearcoat - glTF Extension
- Scattering from Layered Materials - PBR Book
- Autodesk Standard Surface - Layering Model
- OpenPBR White Paper - Mixing
- glTF-Sample-Assets/Models/FlightHelmet - GitHub
- Ray Tracing In Vulkan - RenderDoc
- Radeon™ Developer Panel (RDP) - GPUOpen
- RADV Environment Variables - Mesa 3D Docs
- vulkan-amdgpu-pro - AUR
- amd-vulkan-prefixes - AUR
- Modernizing Granite’s mesh rendering - The Maister
- glTF Sample Models - Sponza
- RDNA Performance Guide - GPUOpen