Preface
目前为止,Foundation 还没有直接,不依赖于外部工具的性能评估工具。同时:之前读过的 【技术精讲】AMD RDNA™ 显卡上的Mesh Shaders(二):优化和最佳实践 提到了剔除部分一些Wave Instrisic的优化还暂时没有实现。鉴于后者效果的衡量也可以通过前者反映,且未来好处良多:索性在本篇对这两个方向进行探索。
内置 Profiler
工具上,NV/AMD 也早有了非常成熟的toolchain,即NVIDIA Nsight Graphics,Radeon™ Developer Tool Suite。CPU侧自己也很早集成了tracy profiler:这些都离不开外部工具的加持。当然:内置工具主要是方便即时反馈。真正有诊断意义的数据还是要从第一方,驱动级工具获取分析的。
时序获取
Query 类 API 覆盖率相当广泛 - Vulkan (1.0+),DX12 等等皆有第一方支持 - 为我们的 RHI 及 Renderer 每个pass添加也并非难事。以下为 Renderer 中节选:
void Execute(size_t thread_id) noexcept override
{
ZoneScoped;
ZoneNameF("<%s>", pass->name.c_str());
*cmd = r->ExecuteAllocateCommandList(pass->queue, thread_id);
(*cmd)->Begin();
(*cmd)->WriteTimestamp(queryPool, RHIPipelineStageBits::TopOfPipe, pass->handle * 2);
(*cmd)->BeginTransition();
for (auto& [res, desc] : (*barriers))
{
res.Visit([&](RHIBuffer* p) { (*cmd)->SetBufferTransition(p, desc); },
[&](RHITexture* p) { (*cmd)->SetImageTransition(p, desc); });
}
(*cmd)->EndTransition();
(*cmd)->DebugBegin(pass->name.c_str());
pass->frameExec = r->mFrameSwapped;
pass->pass->Record(pass->handle, r, *cmd);
(*cmd)->DebugEnd();
(*cmd)->WriteTimestamp(queryPool, RHIPipelineStageBits::BottomOfPipe, pass->handle * 2 + 1);
(*cmd)->End();
}
在这里我们需要的主要是timing/时序信息,故仅需采样Timestamp Queries。在每个pass真正录制前后引入TopOfPipe, BottomOfPipetimestamp引入即可(保守地)估计执行该pass需要至少用时,如图。
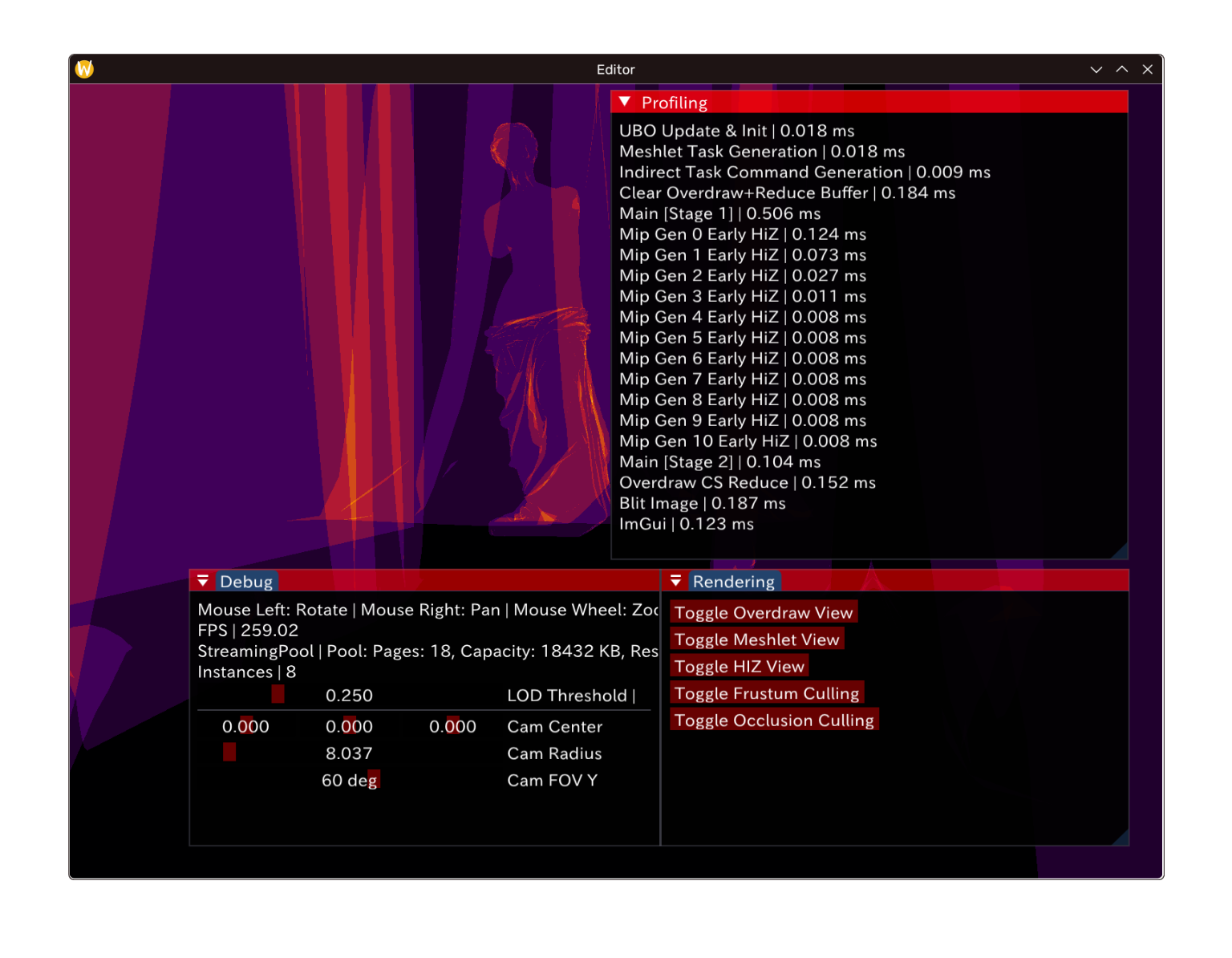 需要注意的是:Pass的执行开始顺序一定,但可能不按该顺序完成。也就是说,即使是在同一个queue上submit,收集到pass的时序是有可能“重叠”的——Queue上的执行并非串行!参见 Ensure Correct Vulkan Synchronization by Using Synchronization Validation(下图)。
需要注意的是:Pass的执行开始顺序一定,但可能不按该顺序完成。也就是说,即使是在同一个queue上submit,收集到pass的时序是有可能“重叠”的——Queue上的执行并非串行!参见 Ensure Correct Vulkan Synchronization by Using Synchronization Validation(下图)。

同时,Foundation 支持Async Compute。两个Queue只会增大“可能并行”的可能性,若存在则在一行内绘制profile时序一定会重叠 - 我们需要分行。
区间分行
可能重叠的区间分配给行内不重叠的几行,又是个什么问题?区间调度 和这很像 —— OS课上学过的最早截止时间调度,这里就可以用到。$O(n logn)$贪心解法如下:
int ImProfilerAssignLanes(Span<ImProfilerSample> samples)
{
std::sort(samples.begin(), samples.end());
// Partition into lanes - work has chance to overlap on the GPU.
int top = 0; PriorityQueue<Pair<size_t, int>, std::greater<>> Q(GLOBAL_ALLOC);
for (auto& sample : samples)
{
if (!Q.empty() && Q.top().first <= sample.startTick)
{
sample.lane = Q.top().second; Q.pop();
Q.emplace(sample.endTick, sample.lane);
}
else
{
sample.lane = top++;
Q.emplace(sample.endTick, sample.lane);
}
}
return top;
}
不过——算法有一个特性会带来一些麻烦:由于“抢占”的是结束时间最早的列,当区间是连续的时候,会出现区间在列之间交替的现象。对负载均衡而言可能是好事,但对我们而言,看起来会很麻烦,如下图:

反思,GPU内能够Overlap的工作是不会太多的:barrier等等都将限制能够并行的pass数量。如上图,只有Clear Overdraw..和async compute部分的工作重在了一起。我们不妨考虑一下另一种贪心做法。这里,我们将尽可能向更早期的行加入区间:
int ImProfilerAssignLanes(Span<ImProfilerSample> samples)
{
std::sort(samples.begin(), samples.end());
// Partition into lanes - work has chance to overlap on the GPU.
Map<int, size_t> Q(GLOBAL_ALLOC);
for (auto& sample : samples)
{
for (int lane = 0;; lane++)
{
if (Q[lane] <= sample.startTick)
{
sample.lane = lane, Q[lane] = sample.endTick;
break;
}
}
}
return Q.size();
}
对行数$K$,时间复杂度是$O(Kn + nlogn)$。最坏情况下$K=n$会退化成一个$O(n^2)$的解法 - 但是事实告诉我们这是不可能的:如前文所述,$K$的值一般很小,基本可以认为是常数。这里的区间效果如下:

效果
最后,整体UI(暂定)如下。以下为开启Async Compute与关闭的时序表现:
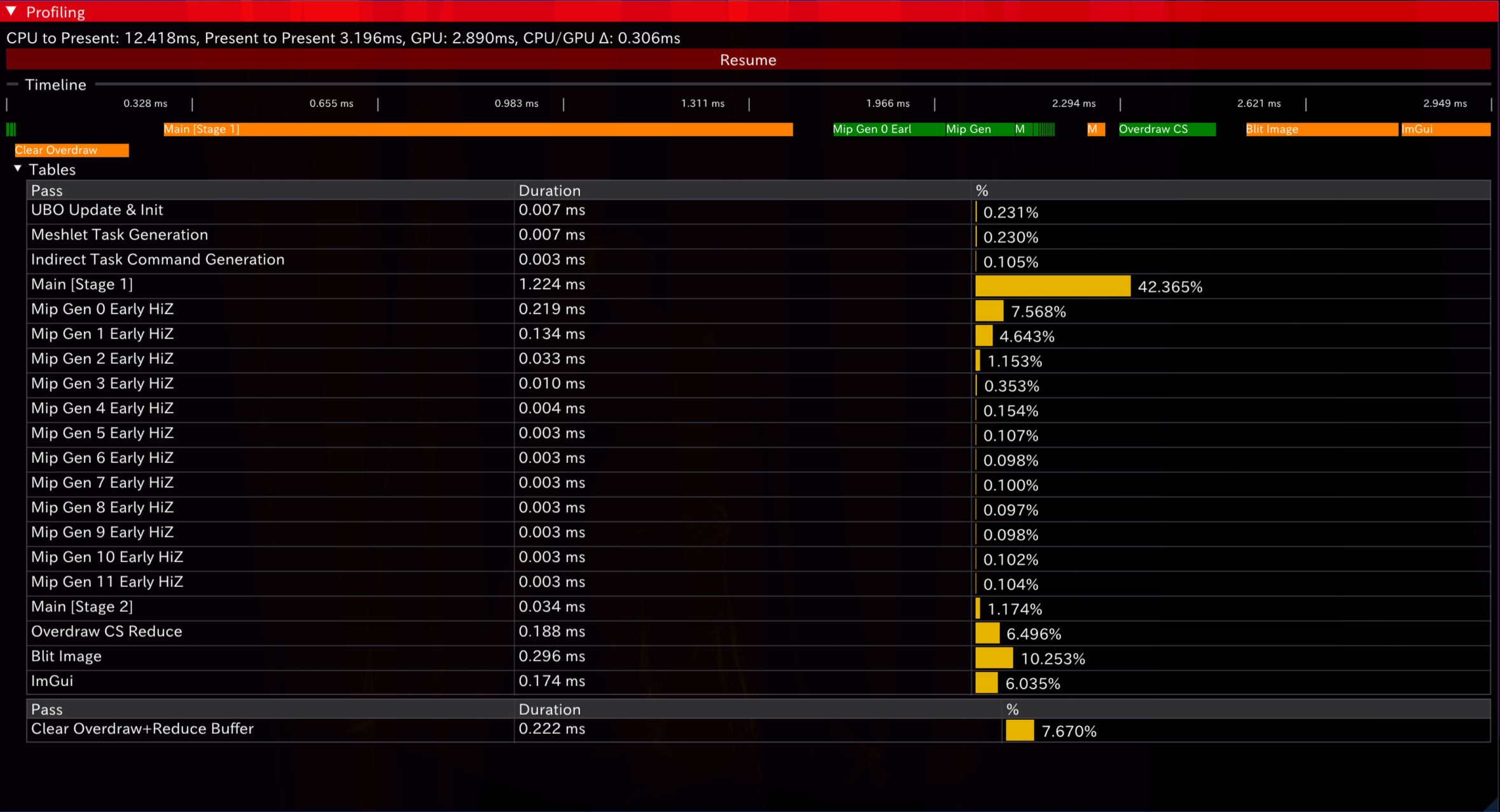
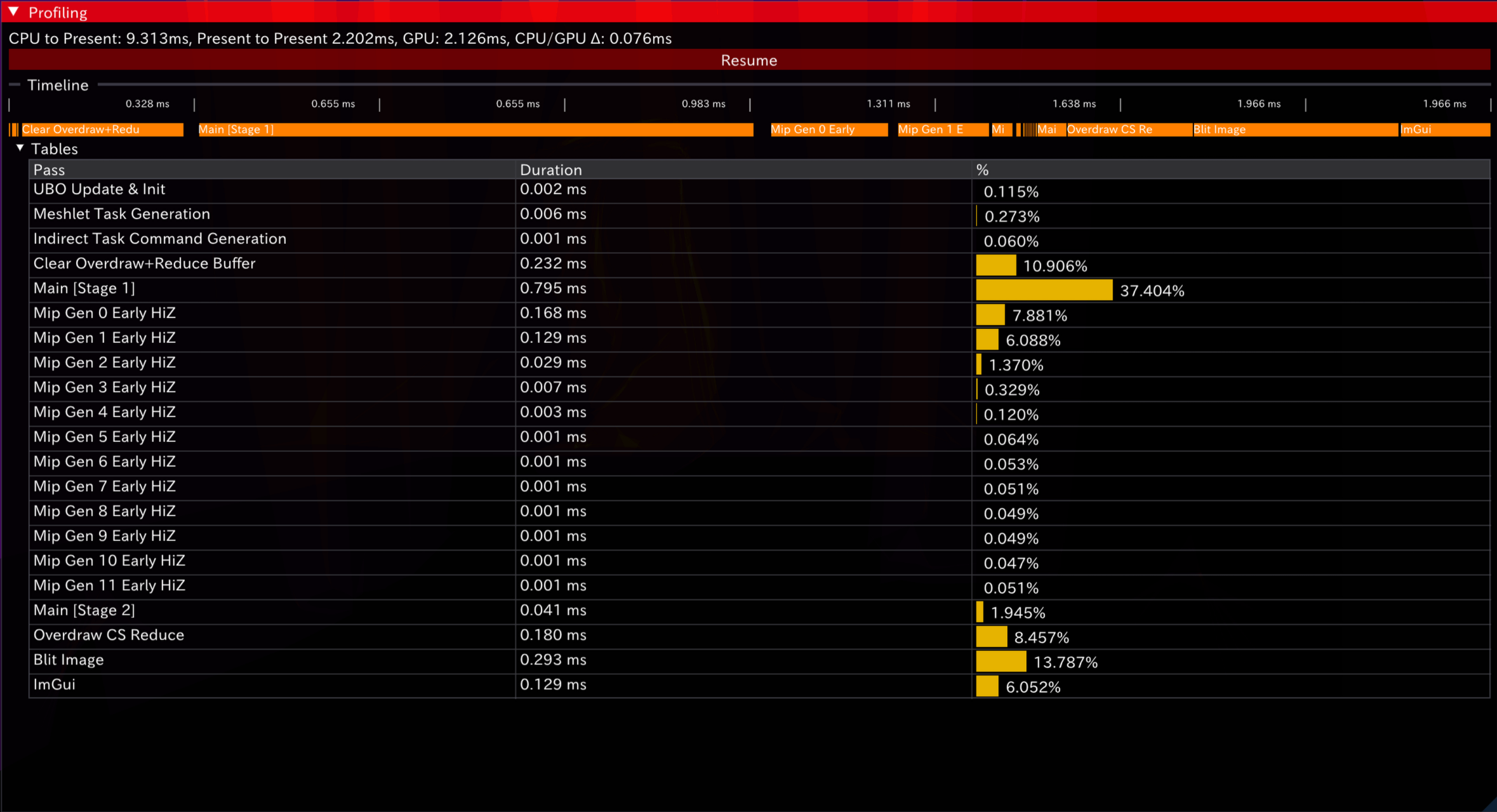
可见,async compute带来的额外同步开销是不可避免的(注意图1中的“空白”部分)。同时在此工作大多串行,overlap效果被同步overhead抵消而反减——后期在pass更复杂,ALU/带宽工作分离程度更高时,优势将更加“显然”。
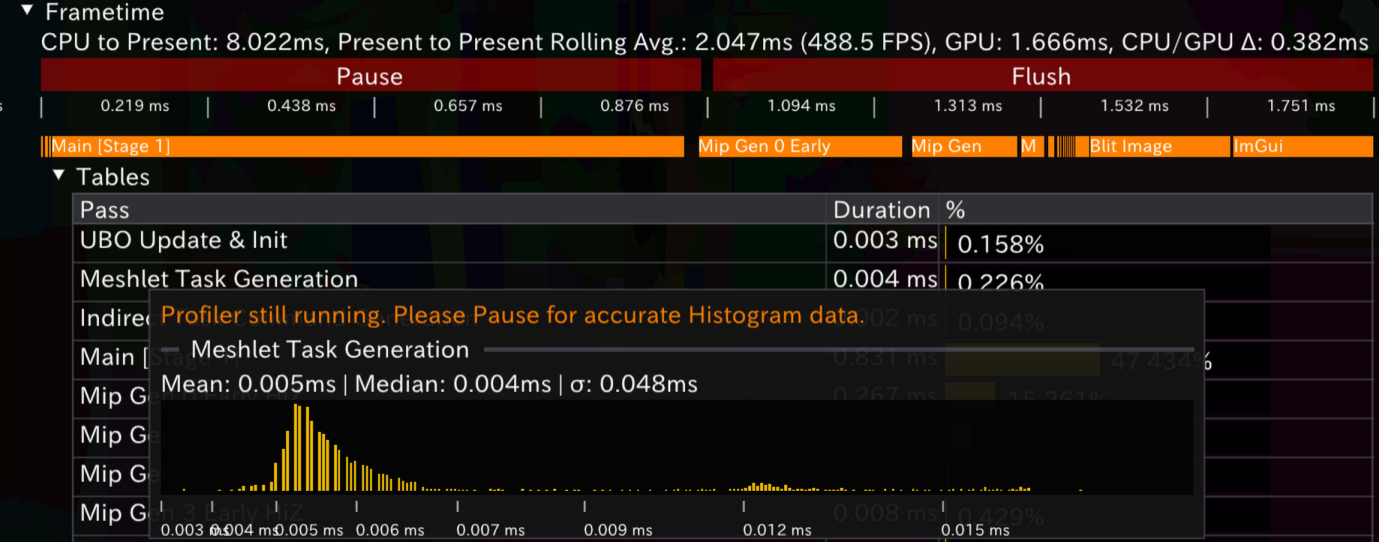
额外的,还有标配直方图等统计量。实现上很粗暴:环形缓冲+排序+binning,这里不多费笔墨。注意时间轴使用了$log_{10}$缩放:这里和tracy 一致。
Wave Intrinsics
SM6.0加入的Wave Intrinsics允许我们更直接且全平台地利用GPU的SIMD潜力来构建compute shader(还有PS/fragment可用的 quad wave - 这里暂时不提)
回忆Task/Mesh shader本身也是compute模型的——这里也可以使用wave/subgroup intrinsics来减少同步上的一些开销。以下是自己在 Task Shader部分用Wave Intrinsic实现cull后meshlet统计的一些笔记。
LDS 实现
回顾当前整理可见meshlet id时 - 我们的实现依赖于LDS/groupshared内存,work group barrier与原子操作 InterlockedAdd
if (visible) {
uint sharedCount;
InterlockedAdd(shared.meshletCount,1,sharedCount);
shared.meshletIndices[sharedCount] = meshletID;
}
GroupMemoryBarrierWithGroupSync();
DispatchMesh(shared.meshletCount,1,1,shared);
- 对于前者,workgroup大小大于wave大小时会在wave之间产生暂停(相反的,小于或等于时会变得不必要——驱动会优化掉这些barrier)。显然,滥用会导致CS线程占有率退化——不过这里的task shader并不能体现这一点。
- 对于后者,并发访问量大时会产生抢占而有退化成串行执行风险;其次,atomic访问的延迟也是一般更高的。
可见,在这里利用wave函数的优化动机主要来自后者——对原子级同时发生的写而言,越少越好。且正如上文所述,这很可能是可以大幅度避免的。
注意:‘可能’取决于GPU真正跑这些shader使用的Wave Size。GPU上可以任何 $2^n$ wave size执行CS。特别地,N卡一般在一个wave跑$32$个线程(CUDA的warp也是这个大小),AMD从前只会跑$64$个——RDNA开始也支持wave32了(图源:RDNA Architecture - GPUOpen)。一个显然,但是消极的策略即为调整workgroup大小为$32$——一个workgroup内最多在这两种硬件上只跑一个wave,缺点也很显然:dispatch会更多,延迟出于学习目的,这里不妨用wave重写LDS同步部分
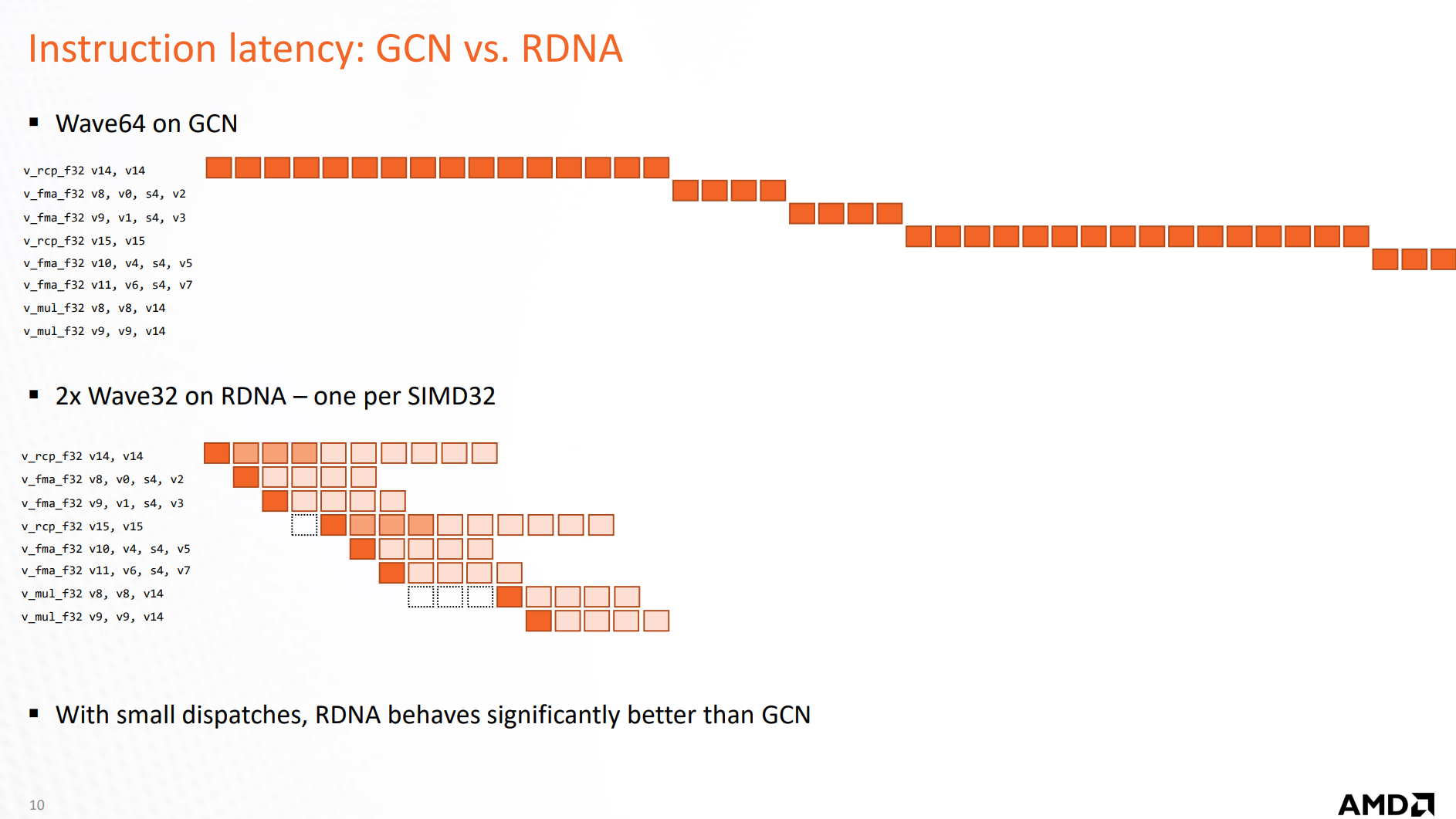
Wave 实现
Wave Instrinsic的出现允许我们不完全依赖与驱动的优化,而构造硬件wave大小无关的“零开销”同步。同时,一系列wave指令也可以加速原来本需要原子访问等的一些操作,这将在接下来的实现中继续解释。
来自 【技术精讲】AMD RDNA™ 显卡上的Mesh Shaders(二):优化和最佳实践 也有提及:
在 amplification shader 执行每个 meshlet 剔除操作时,即检查预先确定的一组 meshlet 的每个元素的可见性时,我们建议每个 amplification shader 线程组至少处理 32 或 64 个元素(如 meshlet)。通过选择对应的 amplification shader 线程组的大小,可以在 RDNA™ 显卡上使用
WavePrefixCountBits和WaveActiveCountBitswave 内置函数来完成剔除。
需要注意的是,原文样例实现做了workgroup在同一个wave上运行的假设:
if (visible)
{
const uint idx = WavePrefixCountBits(visible);
payload.meshletIds[idx] = meshletId;
}
const uint meshletCount = WaveActiveCountBits(visible);
DispatchMesh(meshletCount, 1, 1, payload);
DispatchMesh是以workgroup为同一单位的 - 意味着若workgroup大于wave大小(如WG=64, wave=32),payload访问将出现错误的重叠。wave大小无关的实现需要一些额外的工作:
uint waveVisibleCount = WaveActiveCountBits(visible);
if (waveVisibleCount > 0){
uint waveMeshletOffset = 0;
if (WaveIsFirstLane())
InterlockedAdd(shared.meshletCount, waveVisibleCount, waveMeshletOffset);
waveMeshletOffset = WaveReadLaneFirst(waveMeshletOffset);
if (visible) {
// Output the visible meshlet
uint sum = WavePrefixCountBits(visible);
shared.meshletIndices[waveMeshletOffset + sum] = meshletID;
}
}
shared.instanceID = work.instanceID;
DispatchMesh(shared.meshletCount,1,1,shared);
- 我们假设workgroup大小比wave大小更小,或是正整数倍——因为wave和我们给定的workgroup大小均为$2^n$,因此假设是一定的。
WaveIsFirstLane()保证一组,不同wave各自bump组内meshlet的数目一次WaveReadLaneFirst()向整组广播属于wave的第一个meshlet - 接下来的waveVisibleCount个数的meshlet也将都属于这个waveWavePrefixCountBits()相当于wave中lane/线程对于上述meshlet的位置。
操作数上(仅关注上述部分),假设$N$个可见meshlet,我们将LDS实现每组$N$次的InterlockedAdd降低到了$\frac{WorkGroupSize}{WaveSize}$的常数。最后同样DispatchMesh:注意(来自DirectX Spec)
This function, called from the amplification shader, launches the threadgroups for the mesh shader. This function must be called exactly once per amplification shader, must not be called from non-uniform flow control. The DispatchMesh call implies a GroupMemoryBarrierWithGroupSync(), and ends the amplification shader group’s execution.
DispatchMesh本身也包含一次barrier;注意到LDS实现中前一句也因此多余,上文wave实现中也因此没有额外同步。
注:指定 Wave 大小

SPIR-V 中存在SubgroupSize Built-in 以指定wave大小。但即使添加[WaveSize(N)]修饰,slang编译器貌似并不会emit这个opcode——编译器没有给出warning,不清楚这是什么问题
- Shader
[shader("amplification")]
[numthreads(kMeshWorkGroupSize, 1, 1)]
[WaveSize(kMeshWorkGroupSize)]
void main(uint groupIndex: SV_GroupIndex, uint2 groupID: SV_GroupID) {
const bool early = cullFlags & kCullStageFirst;
const bool late = cullFlags & kCullStageLate;
const bool cullFrustum = cullFlags & kCullFrustum;
const bool cullOcclusion = cullFlags & kCullOcclusion;
...
- SPIR-V
...
[11] OpEntryPoint TaskEXT %main "main" %shared %counter %tasks %instances %primitive %primitive %occlusion %hiz %hizSampler %73 %77 %globalParams
[12] OpExecutionMode %main LocalSize 64 1 1 # <- 仅有localsize
事实上,WaveSize的指定只能保证在支持该wave大小的硬件上能够以该大小运行——对于不支持的硬件则无法执行:编译管线时驱动会拒绝掉。参考 Ten Years Of D3D12 - WaveSize - MJP。指定wave大小即使能用,看起来也没有太大价值..
最后,要用wave并target全平台的话,还是得写支持各种wave大小的shader。
结果
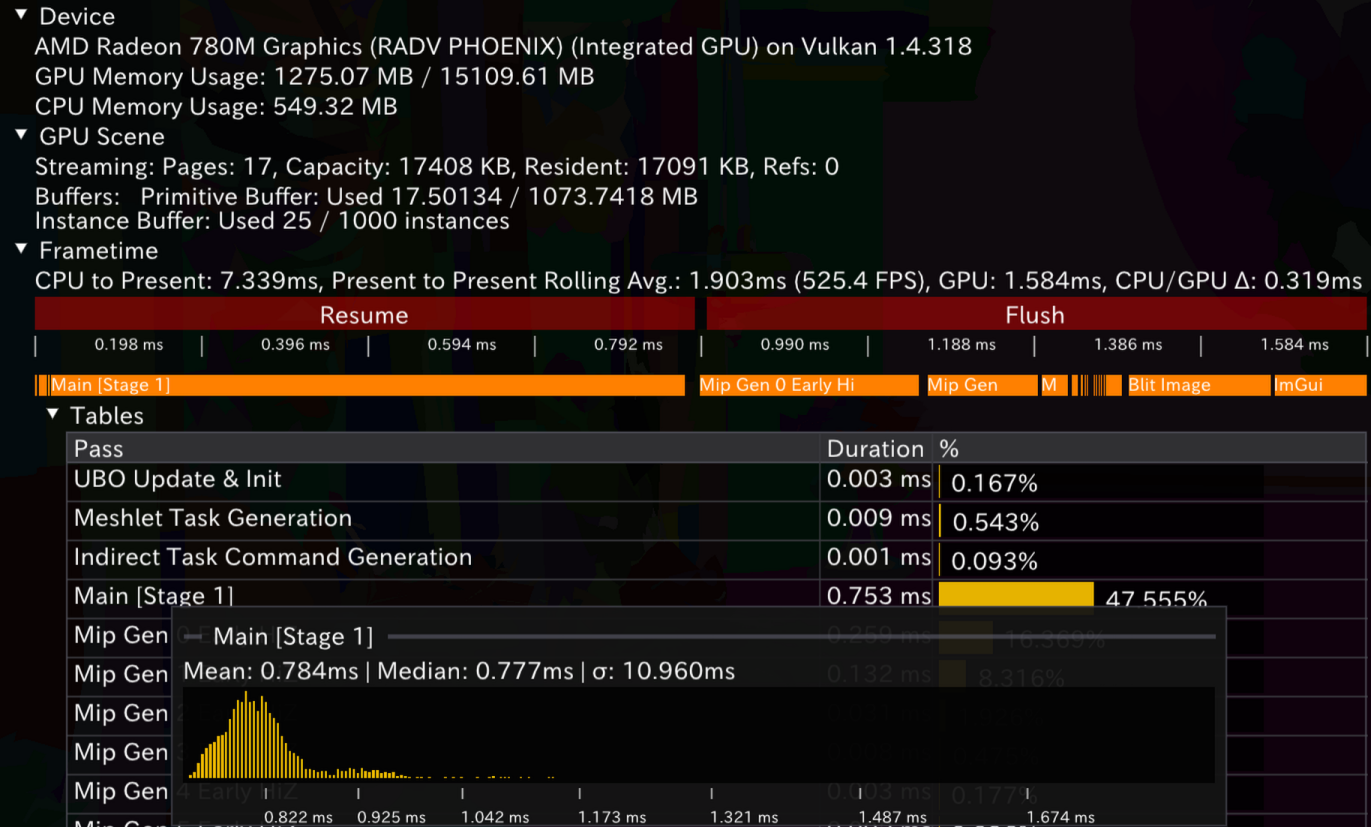
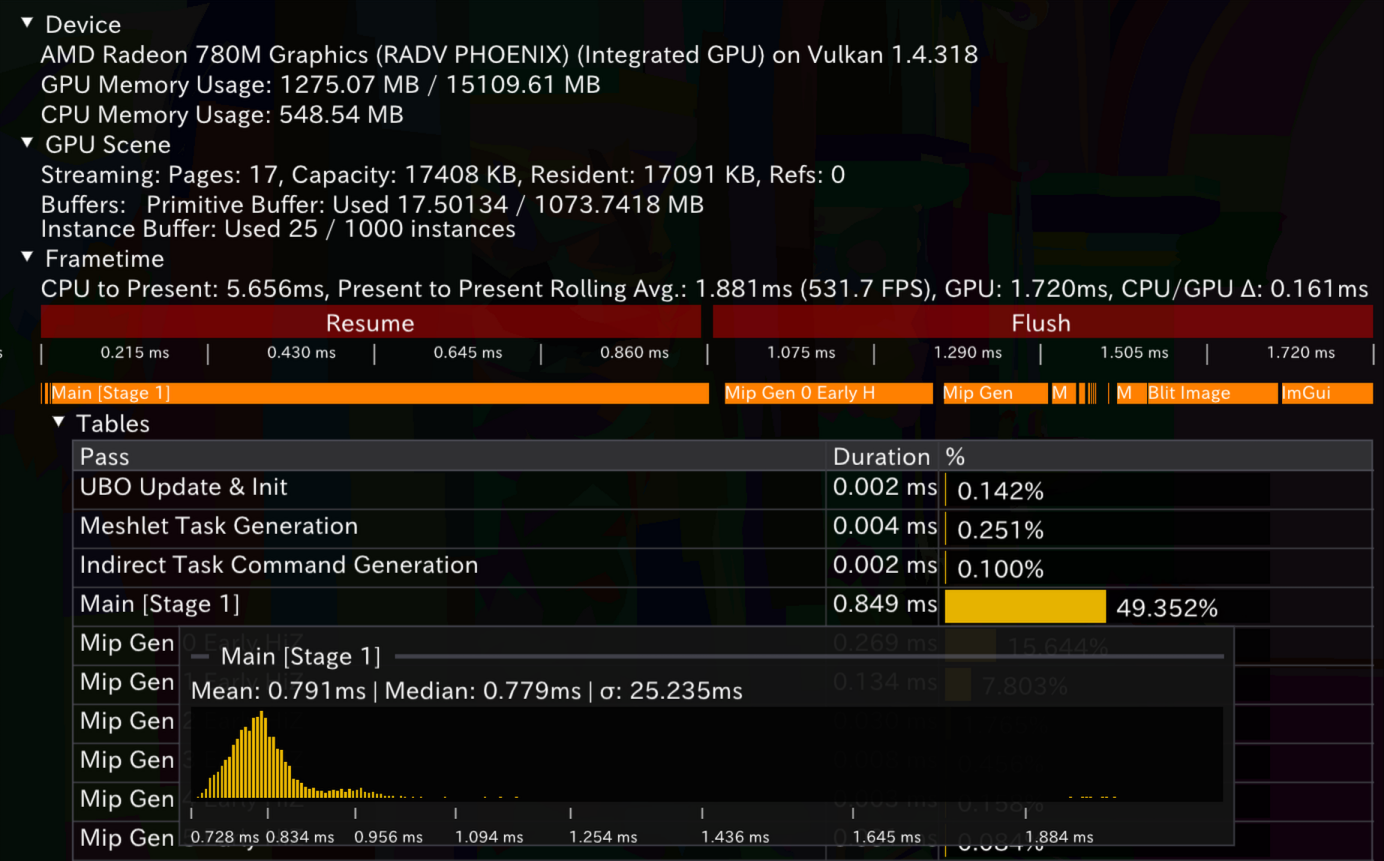
LDS和Wave实现的时序图如下,前后顺序对应。在自己的AMD硬件和WorkGroup大小为64时,提升并不明显。这是期待之中的:毕竟我们的workgroup大小不大(64)。在group很大,同时使用很多wave时,提升的机会将更为显然。
References
- 【技术精讲】AMD RDNA™ 显卡上的Mesh Shaders(二):优化和最佳实践
- NVIDIA Nsight Graphics
- Radeon™ Developer Tool Suite
- tracy profiler
- Vulkan® 1.0.3 - A Specification by the Khronos Group - Queries
- Timing (Direct3D 12)
- Foundation::RenderCore::Renderer Class Reference
- Vulkan Samples - Timestamp Queries
- Ensure Correct Vulkan Synchronization by Using Synchronization Validation
- Interval scheduling - Wikipedia
- 最早截止时间优先调度 - 维基百科
- Wave Intrinsics
- GroupMemoryBarrierWithGroupSync function
- InterlockedAdd function
- Driver will optimize away barriers in some cases - DirectX-Graphics-Samples Issue #140
- RDNA Architecture - GPUOpen
- DirectX-Specs - DispatchMesh
- SPIR-V Specification - SubgroupSize
- Ten Years Of D3D12 - WaveSize - MJP