Preface
迄今为止,Editor渲染方面实现仅处理了单个 Mesh 的最简单情况。接下来我们将正式引入场景加载。
在 CPU 上表达物体间关系的方案诸多——本质上也都是为实现某种Scene Graph。同时,本篇体裁内的最终目标仅仅是为了渲染 GLTF 场景。此后内容也将围绕其结构进行展开。
坐标系细节
我们约定使用右手系坐标系统。即在相机视角,$+X$为右,$+Y$为上,$-Z$为前。这也是Blender等的默认坐标系($+Z$指向相机“内”)
透视及视角矩阵
- 注:$f$与$a$
$$ f = \frac{1}{\tan(fov_y / 2)},a = \text{宽高比} $$
我们想要让$z$轴上,相机处 $ z= z_{n}$ 的NDC为 $z_{ndc} = 1$; 无穷远,或一定$z_{f}$ 处 $z_{ndc} = 0$
理由是充分的。简要地,$[1,0]$映射可大幅改善near plane附件深度精度。详细解释及动机还请参考:
下面直接给出改配置对应透视矩阵,可由代入计算$z=z_n,z_{NDC}=1$, $z = z_f, z_{NDC} = 0$易得
$$ P = \begin{bmatrix} \frac{f}{a} & 0 & 0 & 0 \newline 0 & f & 0 & 0 \newline 0 & 0 & \frac{z_n}{z_f - z_n} & \frac{z_f z_n}{z_f - z_n} \newline 0 & 0 & -1 & 0 \end{bmatrix} $$
- 代入$z_f = +\inf$即可得无穷远版本
$$ P = \begin{bmatrix} \frac{f}{a} & 0 & 0 & 0 \newline 0 & f & 0 & 0 \newline 0 & 0 & 0 & z_n \newline 0 & 0 & -1 & 0 \end{bmatrix} $$
对Vulkan,Viewport的Y轴需要翻转
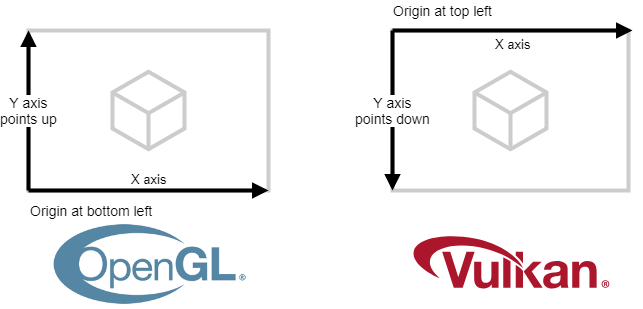
可以考虑直接翻转投影$Y$轴(翻转$P[1][1]$) 。但这样做在其他 RHI 平台又需要二次调整 - 其次,未经过透视变换的量(如法线)与其次空间的position量会产生坐标系不一致——可以理解为什么Unity 会用postprocess仅仅善后Framebuffer
在Vulkan(目前我们唯一支持的 RHI),翻转Viewport/Framebuffer很容易;仅需在
vkSetViewport做翻转并启用shaderDrawParametersextension即可。我们RHI中的实现如下:
RHICommandList& VulkanCommandList::SetViewport(float x, float y, float width, float height, float depth_min, float depth_max, bool flipY) {
CHECK(mAllocator && "Invalid command list states.");
if (flipY)
{
y = height - y;
height = -height;
}
vk::Viewport viewport{ x, y, width, height, depth_min, depth_max };
mCommandBuffer.setViewport(0, viewport);
return *this;
}
这样做,我们的坐标系和Blender,OpenGL与GLTF将完全一致。对视角矩阵的构造如下:$pos=(0,0,0),quat(xyzw)=(0,0,0,1)$的原始变换下,相机将朝$-Z$方向看。
// Forward = -Z
inline mat4 viewMatrixRHReverseZ(vec3 pos, quat rot)
{
mat4 view = mat4_cast(rot);
view[3] = vec4(pos.x,pos.y,pos.z,1.0f);
return inverse(view);
}
GPU Scene
传统地,渲染管线需要在 CPU 组织DrawCalls - 变换,剔除等操作在上传前完成。自 DX11 世代起出现的 Compute Shader模型及ExecuteIndirect使得GPU上生成DC成为可能。
遍历场景的任务移交 GPU,很显然,在图上去跑一遍 DFS 的利用率会非常低下:callstack很深且串行,最多只能利用根节点个 GPU 线程。扁平化,基于数据的场景表达方式更适合 GPU 计算。这点包括 Unreal Engine 在内的大多数现代引擎都有采用。
当然,CPU上的场景遍历也是不可避免的:节点间的Transform变换需要更新子节点的global transform,任何编辑操作也将在CPU上完成后上传至GPU。不过,粒度和频率上都将大幅减少。后期也将讨论利用空间数据结构加速CPU侧场景交互的方案。
Buffer 设计细节
场景仅申请PrimitiveBuffer和InstanceBuffer两部分缓冲区,区分依据为且仅为更新频率。
PrimitiveBuffer:存储 Mesh 几何信息及相关元数据。仅在场景加载或 Mesh 变更时更新- 真正的数据流送(传入且传出)暂不在本篇考虑 - 实现上这将需要一个靠谱的 GPA (General Purpose Allocator) 系统。暂时我们使用简单的线性/Bump Allocator。
InstanceBuffer:存储可能逐帧更新的实例信息。细节上值得注意的有:数据结构大小均一致。注意Shader中没有union的对应概念(Slang支持指针 - 但这并非全平台且限制良多,如并不支持对局部变量取pointer),故不同类型实现为 “tag + user data"结构。
实现上为Ring Buffer。Swapchain会有$N$个Backbuffer - 这意味着最坏情况下,在
Acquire()一帧后会有$N-1$帧的历史场景数据仍在被GPU使用。 避免ROW(Read On Write)风险是必须的 - 方案之一可以是为每个Backbuffer分配一份InstanceBuffer。很显然这很浪费:场景数据量将仅能以上限大小$M$以$O(MN)$的代价存储。环形缓冲则允许‘有多少用多少’ - 代价则为$O(kN)$,其中$k$为场景中实例数。值得注意的是,CPU写入overrun情况将较难调试。但避免的充分必要条件即为预留$MN$空间,假设上界已知。
绑定时,
vkCmdBindDescriptorSets也允许传入Descriptor Dynamic Offset。Shader上可直接就通常的Uniform Buffer方式访问数据,无需额外计算偏移。或者,手动传入offset读取也可取——鉴于该特性的’Vulkanism’ - 出于对未来 RHI 兼容性考虑选择后者。
附:结构体对齐
对于模板Load<T>,Slang 文档仅仅提及 4-byte 对齐需求 - 实际上若参考DXC ByteAddressBuffer Load Store Additions,我们的结构体需要地址和其对齐要求最严格(最大)field对齐。
The layout of the type mapped into the buffer matches the layout used for
StructuredBuffer. ThebyteOffsetshould be aligned by the size (in bytes) of the largest scalar type contained within typeT. For instance, if the largest type is uint64_t,byteOffsetmust be aligned by 8. If the largest type isfloat16_t, then the minimum alignment required is 2.
这里做个小记,未来对mesh数据进行量化的时候(如使用half存储float16数据)需要避免踩坑。
“Draw Scene” GPU-command
我们将不考虑传统Vertex管线而直接实现Meshlet整套 GPU Driven 管线。子标题名来自 GPU-Driven Rendering Pipelines - Sebastian Aaltonen SIGGRAPH 2015
回忆Mesh Shader管线可选的前置Task/Amplifcation Shader Stage——生成Meshlet “Drawcall” 本身可以来自这个几乎是Compute Shader(除仅能在Graphics Queue上跑)的环节进行。命令对应 DrawMeshTasks (Vulkan中的VkCmdDrawMeshTasksEXT)
鲜为人知的还有 DrawMeshTasksIndirect (Vulkan中的VkCmdDrawMeshTasksIndirectEXT) —— 这里可以从(或许是)Compute Shader 生成的 command buffer 从 GPU(驱动)dispatch Task Shaders,进一步解放 CPU (用户侧)需求。
驱动层实现细节还请参见:
- Task shader driver implementation on AMD HW - Timur
- 【技术精讲】AMD RDNA™ 显卡上的Mesh Shaders(一): 从 vertex shader 到 mesh shader
- Using Mesh Shaders for Professional Graphics - NVIDIA
完整 Dispatch Chain
综上,我们完整的Dispatch链如下,处理对象粒度递增。(CS: Comptue Shader)
CS Dispatch | CS Submit | Task DrawMeshTasksIndirect | Task->Mesh DispatchMesh |
|---|---|---|---|
| 产生连续存储非空 Task 命令及计数 | 产生 Indirect Task Dispatch 命令 | Meshlet的自适应 LOD 选择+剔除,并产生DispatchMesh在同一Pipeline进行 | 三角形剔除,继续到Fragment/Pixel Stage(略) |
需要注意的是,Task-Mesh属于同一管线。故Task中的DispatchMesh仅能为0或1个。为此在CS Submit时可进行分组,对实例$N$ 个 Meshlet产生$\lceil \frac{N}{WorkGroupSize}\rceil $个 Task Shader Indirect。
最后——在 CPU 上,准备好前置 Buffer 之后的Dispatch仅需一句DrawMeshTasksIndirect
实例化效果
在不进行任何剔除的情况下,性能指标及效果如图。共$10^3$的斯坦福小兔子实例,模型均复用上述PrimitiveBuffer同一指针。
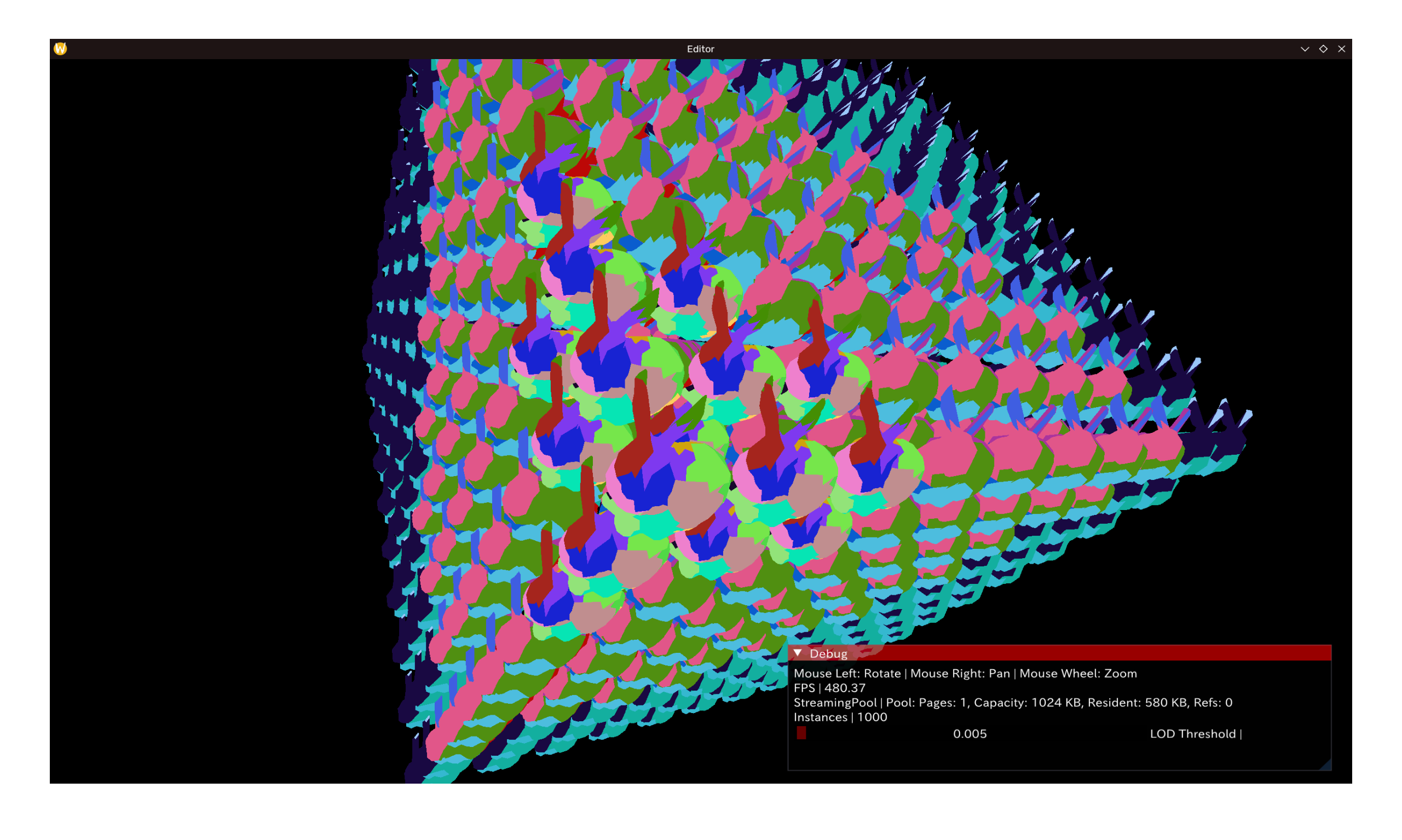
注: 在 Windows 进行调试时发现在以下(个人)配置中可稳定产生VK_ERROR_DEVICE_LOST
- Pipeline 内含 Task Shader 并使用
vkCmdBindPipeline绑定,Submit()即丢设备 - AMD Software: Adrenalin Edition 25.11.1 (2025/11/06)
- Radeon 780M Graphics (本子集显)
包括 官方 Sample 中的 mesh_shader_culling 也可复现(= =||)。后续若能成功Debug将在此处更新——在此之前,后续测试都将在我的 Arch Linux 机器上运行。
GLTF Scene
进而加载真正的场景文件也将很简单——当然,这是建立在只完成spec很小一部分内容的前提上的。我们暂时要做的是:
- 场景树到global transform
- 静态mesh表现
- 有限的pbr材质支持
场景加载涉及 JSON 解析等,这里直接使用 cgltf,实现上参考 zeux/niagara - scene.cpp 。场景自定义序列化自然为必要,届时暂不考虑复用glTF格式。
RAII C指针
至于为什么要这么做:exception unwind自动解构和其他early out机会。我们的CHECK_MSG macro实际是在产生异常的 - 如此在解析中间出事也不会leak。实现如下——这个pattern在别的地方也会经常用到。
cgltf_data* data = nullptr;
UniquePtr<cgltf_data, decltype(&cgltf_free)> raii(data, &cgltf_free); // C pointer with RAII
{
cgltf_result result = cgltf_parse_file(&options, path.data(), &data);
CHECK_MSG(result == cgltf_result_success, "Scene load failure: {}", static_cast<int>(result));
...
}
解析细节
暂时避免OOP/ECS一套轮子,我们只做到:
void LoadGLTF(StringView path, Vector<FMesh>& outMeshes, Vector<FInstance>& outInstances, Vector<FCamera>& outCamera)
从glTF场景文件产生
FMesh,FInstance列表和其他我们想要的东西FInstance包含全局(global) transform及FMeshindexstruct FInstance { float3 transform; quat rotation; float3 scale; uint32_t meshIndex; };outMeshes[FInstance::meshIndex]即为对应 mesh 数据。定义参考前文。
实现上比较简单,不多阐述。需要注意的是glTF中的primitive概念的命名比较神必,你以为是三角形这种几何 Primitive,实际上…
Meshes are defined as arrays of primitives. Primitives correspond to the data required for GPU draw calls. Primitives specify one or more
attributes, corresponding to the vertex attributes used in the draw calls. Indexed primitives also define anindicesproperty. Attributes and indices are defined as references to accessors containing corresponding data. Each primitive MAY also specify amaterialand amodethat corresponds to the GPU topology type (e.g., triangle set).
这里对应一个drawcall,理解成自己需要一个单独shader渲染就好。
序列化
Meshlet及LOD生成代价不低,缓存必要性存在。序列化细节并不多,这里一笔带过。形式如下:
template<> void FSerialize(FWriter& w, FMesh const& obj)
{
FSerialize(w, obj.vertices);
FSerialize(w, obj.lods);
FSerialize(w, obj.dag);
}
...
const uint32_t kSceneMagic = 0xDEADDEAD;
void FSerialize(FWriter& w, Vector<FMesh> const& meshes, Vector<FInstance> const& instances,
Vector<FCamera> const& cameras)
{
FSerialize(w, kSceneMagic);
FSerialize(w, meshes);
FSerialize(w, instances);
FSerialize(w, cameras);
}
// other structs...
最近在 SonyHeadphonesClient rewrite里做过自动序列化代码生成,未来结构体太多(不太可能)时或许也可以采用。但目前结构体复杂程度不会太高,序列化部分均为手写。
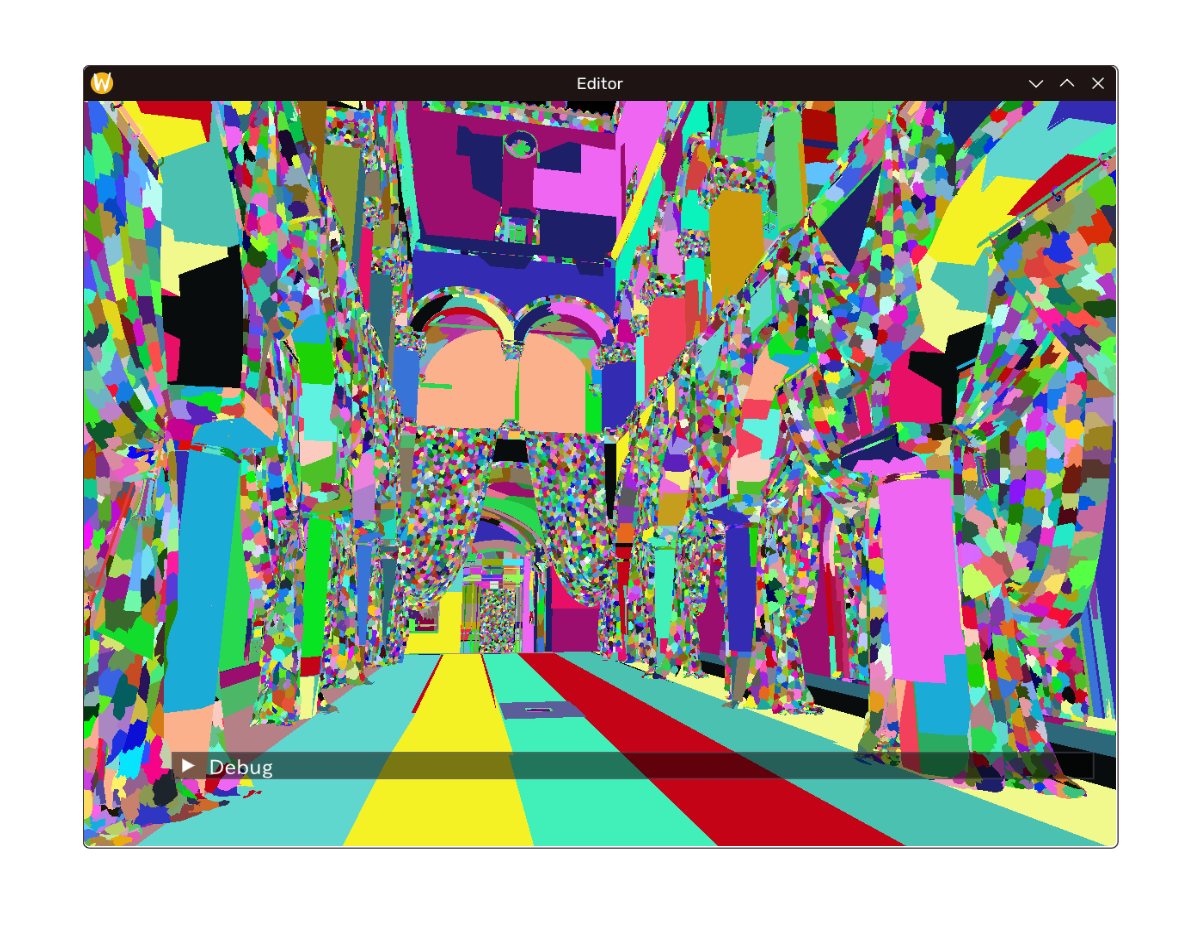
效果
仍然只可视化 Meshlets,最低 LOD 阈值渲染Intel Sponza的效果如下。
材质与 Bindless
不像 D3D12 有ResourceDescriptorHeap,Vulkan 的 Bindless状况比较“非官方”。这里采用的方案为对申请一个Descriptor Set,然后启用runtimeDescriptorArray(Vulkan 1.2 Core)按需更新。Shader中允许这样的使用(来自MipGeneration 样例):
texture2D textures[];
[shader("fragment")]
float4 fragMain(float2 uv: TEXCOORD0) : SV_Target
{
return textures[pc.binding].SampleLevel(sampler, uv, pc.mipReady);
}
CPU Binding 更新也很直接。详见实现。不过,在真正实现shading之前…
Overdraw
图像 Atomics
直觉的你也许会想到可以用Alpha Blending,但是代价不谈,Primitive 顺序无关的“Blending”(OIT)实现是非平凡的。实现上有像素级链表和其他的一些Hack - 细节上未来实现透明 Raster Pass 再讲。
这里,alpha blending 是不必要的。imageAtomicAdd 允许在 Fragment Shader 里同样进行原子操作 - 注意 Slang 中暂时不含该intrinsic,需要 import glsl 引入。参见 https://github.com/shader-slang/slang/issues/4120;Shader 部分如下,注意overdraw是R32ui材质,先前也需要 CS 清空。
// https://github.com/shader-slang/slang/issues/4120
import glsl;
[[vk_binding(5,0)]] RWTexture2D<uint32_t> overdraw;
[shader("fragment")]
Fragment main(V2F input, float2 fragCoord : SV_Position /* pixel space */)
{
Fragment output;
output.color = float4(input.normal, 1.0);
imageAtomicAdd(overdraw, int2(fragCoord), 1);
return output;
}
RenderDoc中可视化如图:
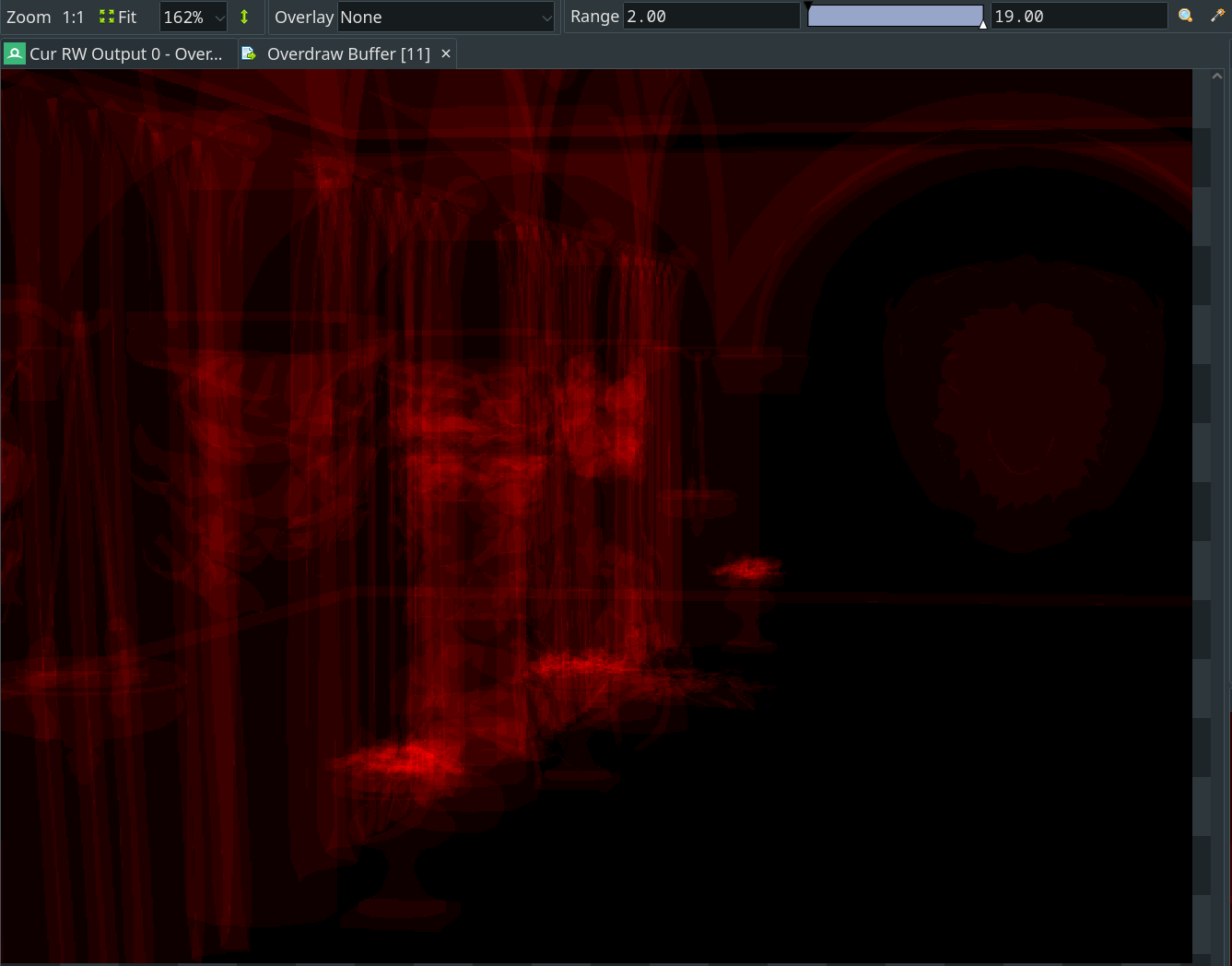
并行 minmax
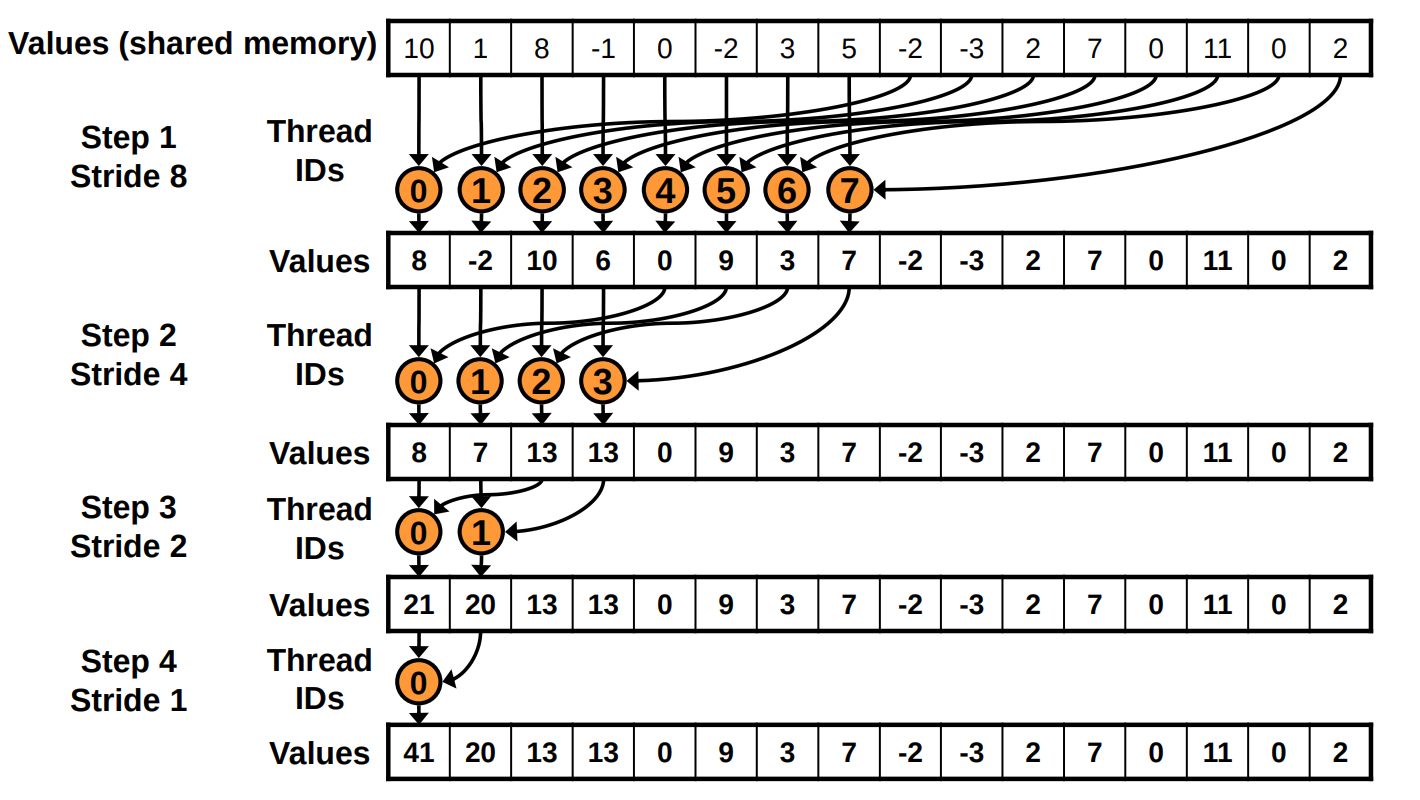
显然,可视化也需要知道像素范围的上下界。这里属于 Reduction 类问题 - 实现上理论最优的均为分治算法,如图(来自Optimizing Parallel Reduction in CUDA - Mark Harris)
Mip Chain 生成实际上正式该类算法的一种实现,包含多次 reduction kernel/CS dispatch。这里的thread占有率(occupancy)会是最优的 - 但是dispatch间不可避免地存在barrier,overhead在此并非平凡。
同时,在这里我们并不需要中间mip。以下为折中(偷懒)方案之一:单次 Dispatch,WorkGroup单位求max后,合并到全局atomic:其存在的可能contention即为$O(\frac{N}{WorkGroupSize})$,其中$N$为总像素数。当然,总的时间复杂度仍然是$O(N)$
利用wave intrinsic,易得的优化空间也存在,这里参考 【技术精讲】AMD RDNA™ 显卡上的Mesh Shaders(二):优化和最佳实践 的部分内容。
struct PushConstant {
int w, h;
}
[[vk::push_constant]] PushConstant pc;
Texture2D<uint32_t> texture;
RWStructuredBuffer<Atomic<uint32_t>> globalMax;
groupshared Atomic<uint32_t> groupMax;
[shader("compute")]
[numthreads(16, 16, 1)]
void main(uint2 tid: SV_DispatchThreadID, uint gid : SV_GroupIndex) {
groupMax = 0;
GroupMemoryBarrierWithGroupSync(); // Init
uint32_t value = 0u;
if (tid.x < pc.w && tid.y < pc.h)
value = texture.Load(int3(tid.x,tid.y,0));
uint32_t waveMax = WaveActiveMax(value);
if (WaveIsFirstLane())
groupMax.max(waveMax);
GroupMemoryBarrierWithGroupSync(); // Wait for all waves
if (gid == 0)
globalMax[0].max(groupMax.load());
}
另外的,单次 Mipmap 生成魔法也存在,即 https://github.com/GPUOpen-Effects/FidelityFX-SPD——后面再提。
效果
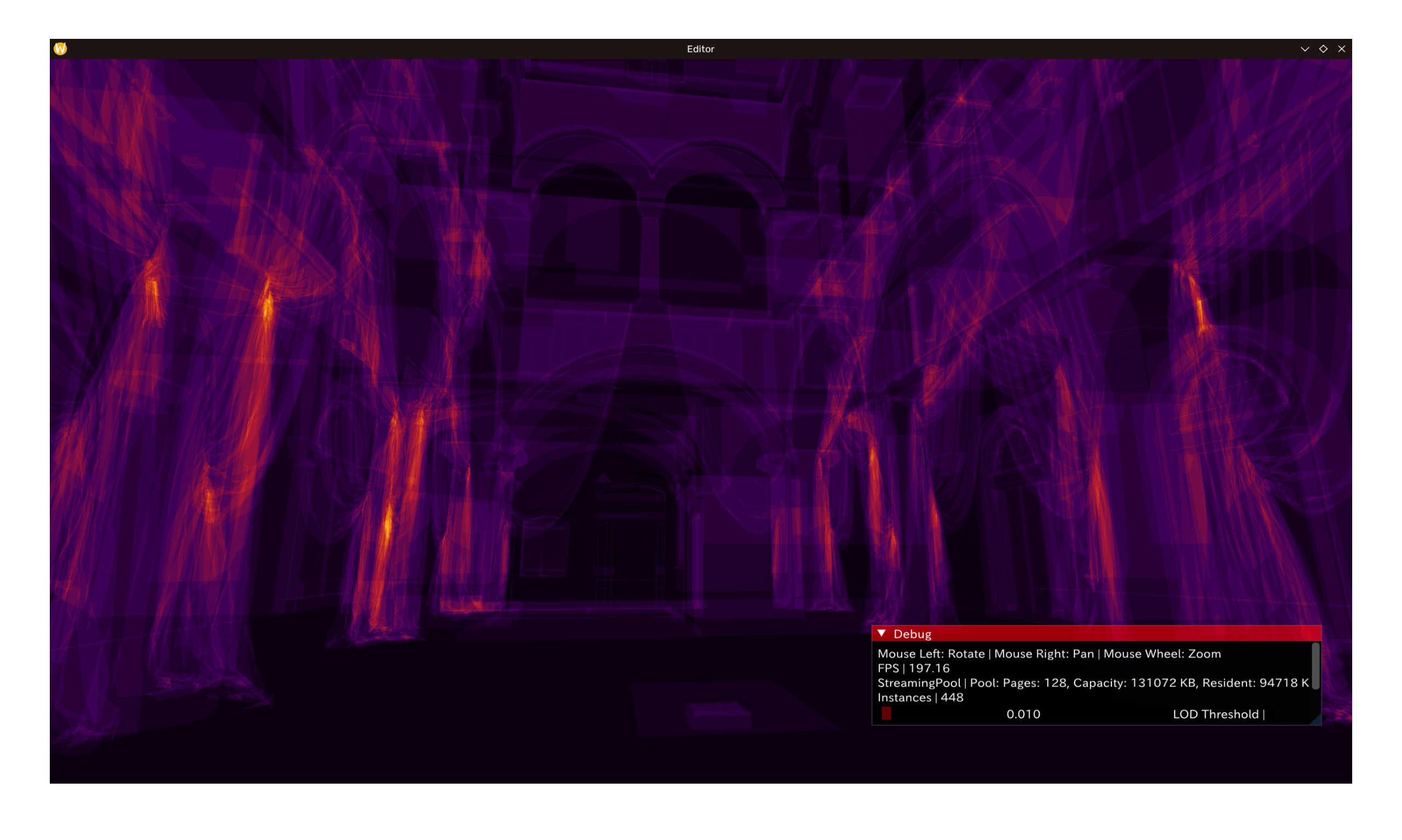
Culling
剔除,裁剪…怎么翻译都好,后文将以cull指代渲染中被省略的物体。
CPU 上的剔除暂不讨论 - 毕竟目前为止还不包括场景上Editor内的互动,不过届时能够直接$O(log N)$ Raycast 是需要这些东西的。接下来的几个手段将无一例外在 CS 中实现。
视锥剔除(Frustum Culling)
或许是最直接 - 也最容易弄错的一种。概述如下:NDC空间的正方体视锥变回世界坐标后可以由六个平面定义,及对应near,far,和上下左右。体积盒在之中的,在透视变换后必要不充分会贡献渲染结果。
“在之中”判断即为平面-体积相交问题。对于AABB长方体盒而言,有相当多的edge case要考虑。正确cull是很难的 - 鉴于我们的bounding box皆为球体,这里仅留下几个链接作为参考:
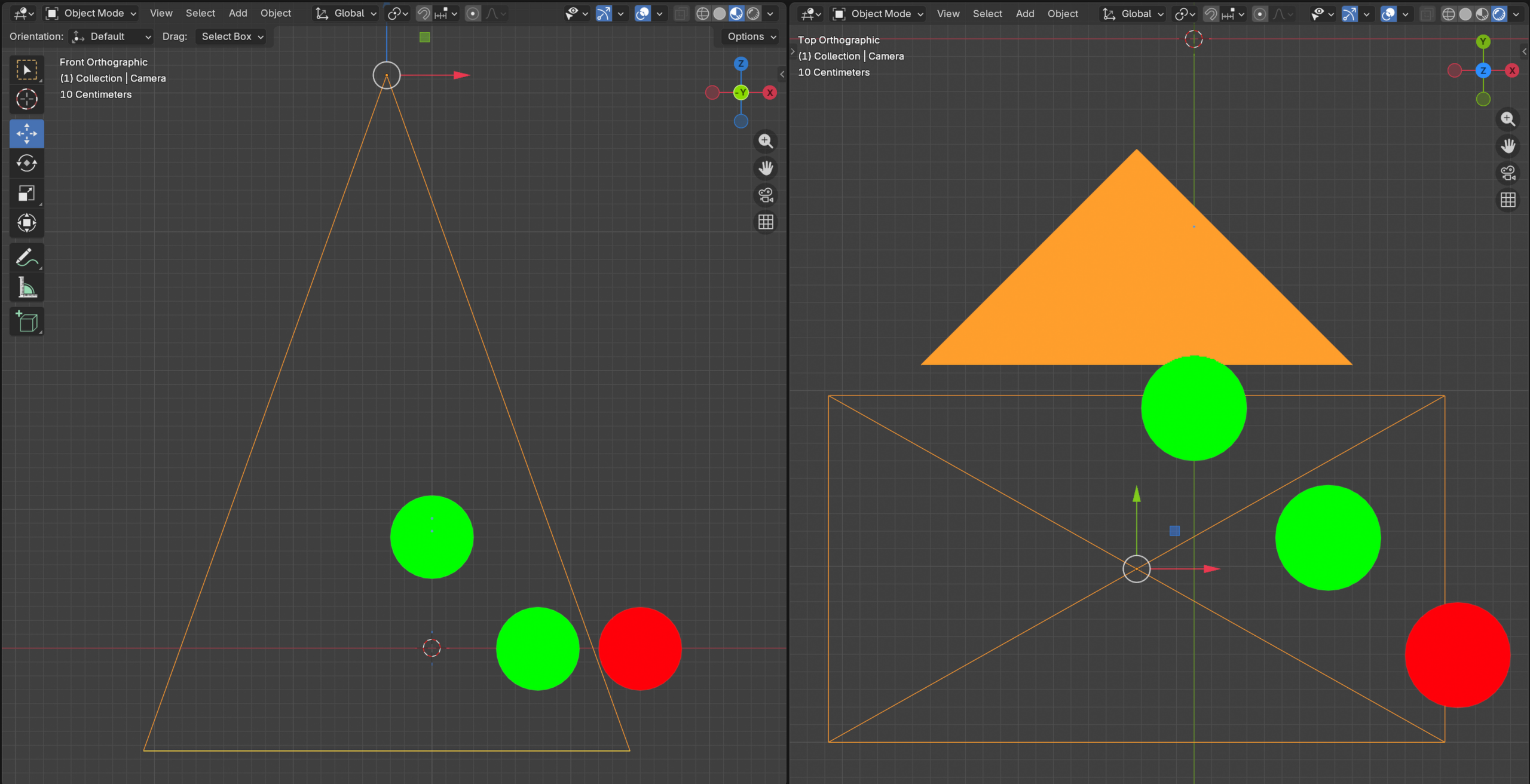
对于球体,检测要简单得多。在View Space,定义各平面为$(a,b,c,d), ax + by + cz = d$,有球体$(x,y,z,r)$
如图,上下左右平面必经过view space原点。故这些平面简化为$ax + by + cz = 0$
注意,目前的透视矩阵是对称的。意味着对于左平面$ax+cz=0$,右平面即为$ax-cz=0$;上下即为$by \pm cz = 0$
我们记左右平面$a,c$为$i,j$,上下平面$b,c$为$k,l$。以左右为例,球体与视锥相交即为解圆心-平面距离: $$ \begin{align*} ix + jz &\ge -r \quad (\text{左}) \ -ix + jz &\ge -r \quad (\text{右}) \end{align*} $$
可化简为 $$ jz \ge -r + |ix| \implies jz \ge |ix| -r $$
对上下同理,得到化简结果 $$ lz \ge -r + |ky| \implies lz \ge |ky| -r $$
Shader实现将很简单。
true当且仅当球体未被剔除。bool frustumCull(float4 ijkl /* [left ac:ij] [top bc:kl] */, float3 center /* view */, float radius /* scaled */, float zNear) { float ix = abs(ijkl.x * center.x); float ky = abs(ijkl.z * center.y); float jz = ijkl.y * center.z; float lz = ijkl.w * center.z; return (center.z >= -zNear) && (jz >= ix -radius) && (lz >= ky -radius); }平面可以取NDC内几点利用投影矩阵逆求叉积取得。或者,也可以注意到view space内的几个系数其实很容易取得。Fast Extraction of Viewing Frustum Planes from the WorldView-Projection Matrix 告诉我们abcd系数为:左平面:$P_3 + P_0$,上平面:$P_3 - P_1$
别忘了
glm/GLSL的矩阵存储是默认列优先(column-major,下面竖列),而正常线代书写基本为行优先。方便记忆,设大小4方阵, $M$和glm矩阵$m_{ij}$。显然的,方阵转置即可在二者间转换。 $$ M = \begin{bmatrix} m_{00} & m_{10} & m_{20} & m_{30} \newline m_{01} & m_{11} & m_{21} & m_{31} \newline m_{02} & m_{12} & m_{22} & m_{32} \newline m_{03} & m_{13} & m_{23} & m_{33} \end{bmatrix} $$以上,$ijkl$系数计算如下
// (i,j,k,l), where left/right planes are ix +- jz = 0, top/bottom planes are ky +- lz = 0 inline float4 planeSymmetric(mat4 proj) { mat4 projT = transpose(proj); float4 left = projT[3] + projT[0]; // (m41 + m11, m42 + m12, m43 + m13, m44 + m14) float4 bottom = projT[3] + projT[1]; // (m41 + m21, m42 + m22, m43 + m23, m44 + m24) // Normalize left /= length(left.xyz()); bottom /= length(bottom.xyz()); return {left.x, left.z, bottom.y, bottom.z}; }
效果
球体bounding box是相对保守的 - 对于较大的被cull对象会存在假阴性(剔除少了)。不过,效果可见一斑,如下图开启前后展示。
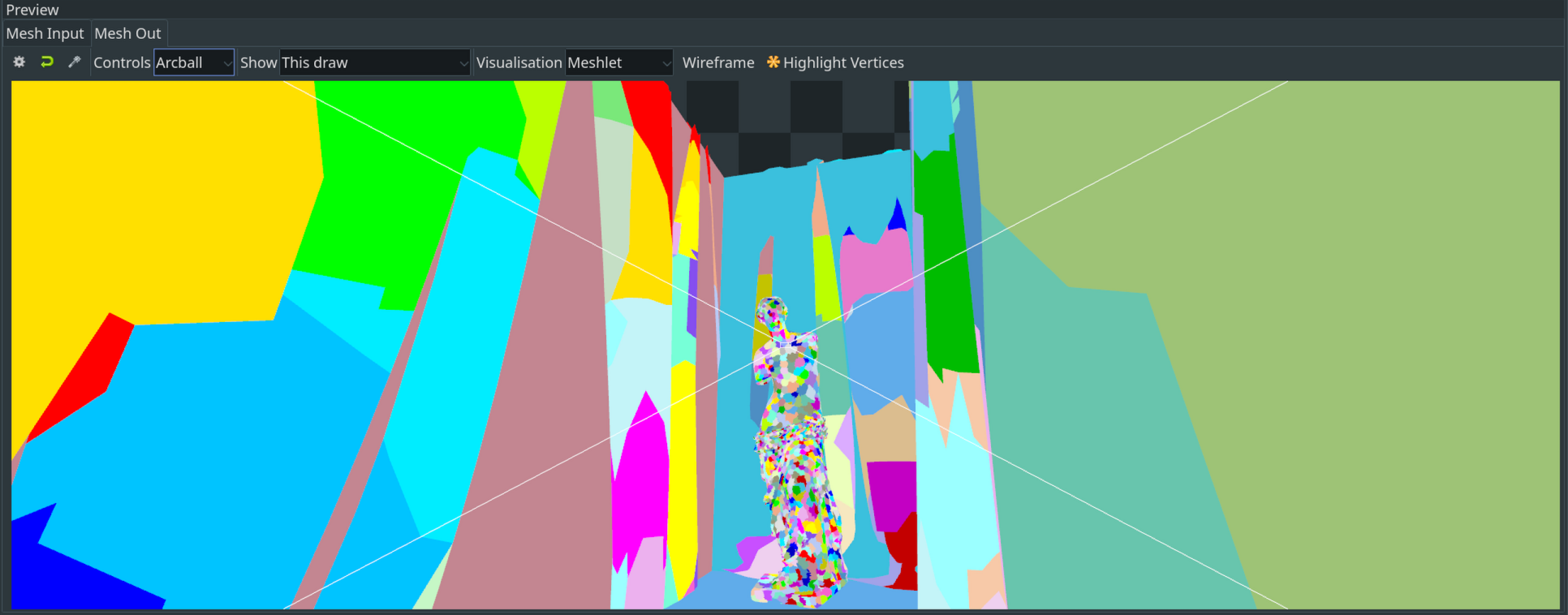
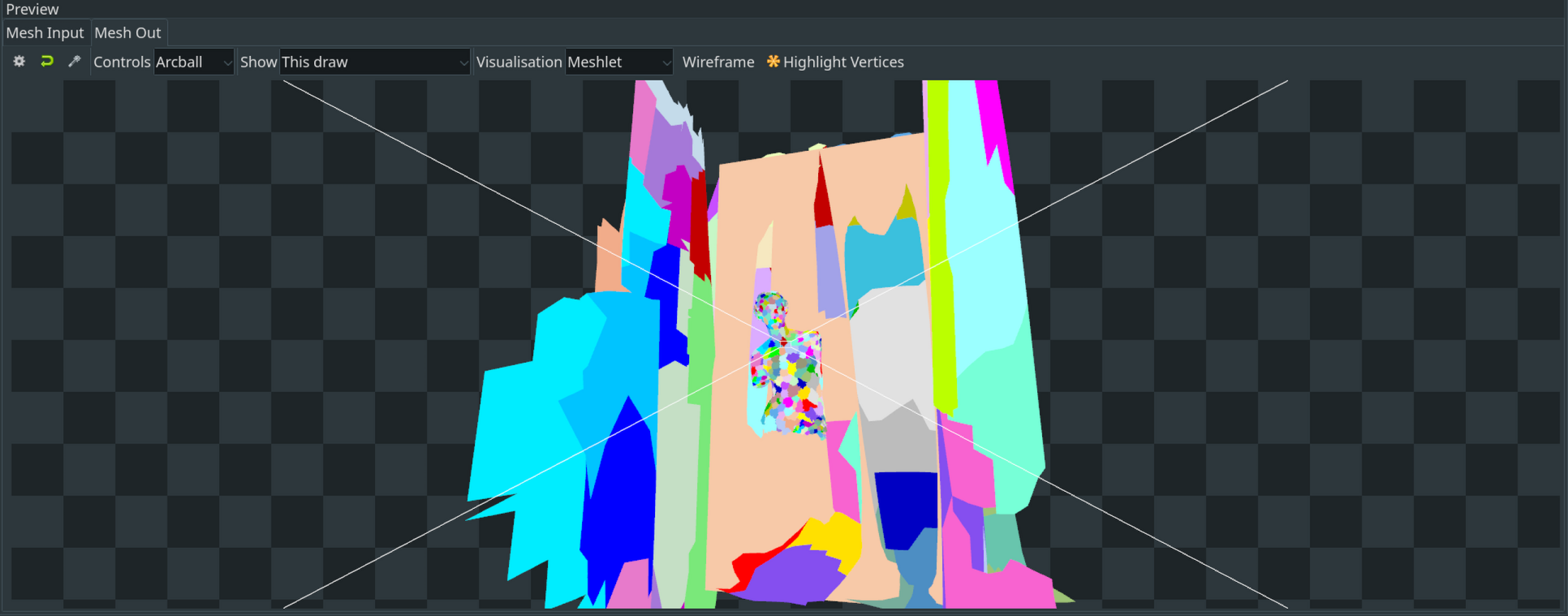
遮蔽剔除(Occlusion Culling)
视锥剔除并不能解决多个物体重叠而互相遮蔽的问题。传统的,有depth prepass这样提前渲染zbuffer来利用光栅器Early Z剔除不必要重叠PS工作的方法。在 UE4, Unity URP的Forward+都有实现。另外还有Occlusion Query等的方法在RTR4中也有所提及,这里不介绍。
HZB

HZB/Hierarchal Z Buffer Cull 则是可以利用mip chain对bounding box直接进行剔除的手段。RTR4 p846也有所提及。
直接利用bounding box在屏幕空间的投影直接对zbuffer逐像素比较可以完成对其剔除的任务,但这是极为昂贵的,同时不必要。假设zbuffer近1远0,深度远值更小,我们做出以下断言:
- 直觉的,REJECT的充分条件是zbuffer该区域的深度中,【全体】比bbox屏幕空间内的最大深度【更大】。
- 取反则为:PASS的必要条件是,zbuffer该区域的深度中,【存在】比bbox屏幕空间内的最大深度【小于等于】的值
想必不用latex也看得懂 那么,PASS前提即可化简为区域内【最小值,小于等于】bbox【最大深度】。
区域内快速($O(1)$)求最小值正是HZB在这里的目的。转RTR4 p848:mip一共$n$级,投影后的bbox最长边像素大小(在HZB Mip 0中)为$l$,我们采样的mip为: $$ \lambda = min(\lceil log_2(max(l, 1))) \rceil, n - 1) $$ 这样,越大的occluder,要采样的mip等级是越高的。真正采样的像素数即为$(x\cdot\ 2^{-\log_{2}x})^2$恒等于$1$,但是注意:该式是保守的。观察下图:
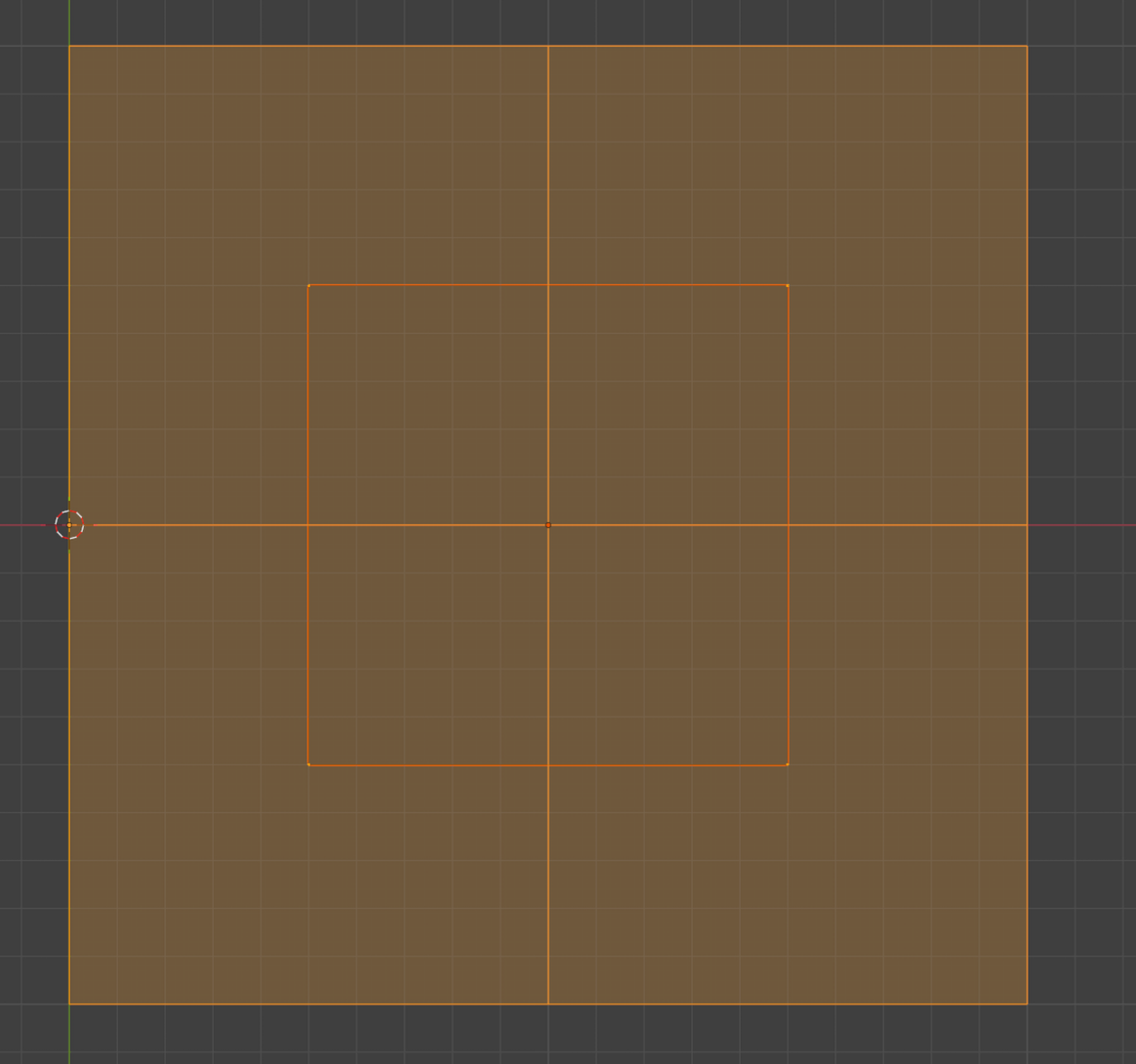
假设投影到aabb,我们的矩形完全可以落在四个texel之间的位置。这意味着,最坏情况下的像素数其实是4 - 上面的向上取整应该为向下取整。不过实践上,向上取整的结果可以接受 - 如此只会(保守地)带来假阴性,而能导致该情况的bbox往往是几个像素大小的——绘制代价并不太大,niagara 也采用了后者方案。
HZB (Mip Chain)生成
前文也有所提及 - 我们将对一张$2^w * 2^h$材质生成中间直到$1*1$的所有mip。在 DX 11 世代甚至有相关 API 让驱动帮你干这个活,当然现代图形API中是见不到的。
自己生成可以如前文所述,多次dispatch,每次将分辨率减半,重复到$1*1$为止;或者利用FFXSPD这样的高级发明单次dispatch搞定——省事起见先选择前者()效果如下,注意:downsample时需利用VK_SAMPLER_REDUCTION_MODE_MIN (默认求平均)- 回忆我们的zbuffer是近1远0,因此每次采样取最小值。效果如图:

Two-Phase Occlusion Culling
在书上再翻几面,可以找到 GPU-Driven Rendering Pipelines - Sebastian Aaltonen SIGGRAPH 2015 介绍的 Two-Phase Occlusion Culling。其中 depth pyramid 即为HZB - Nanite中也实现了这样的方法(见 Nanite A Deep Dive p19)。
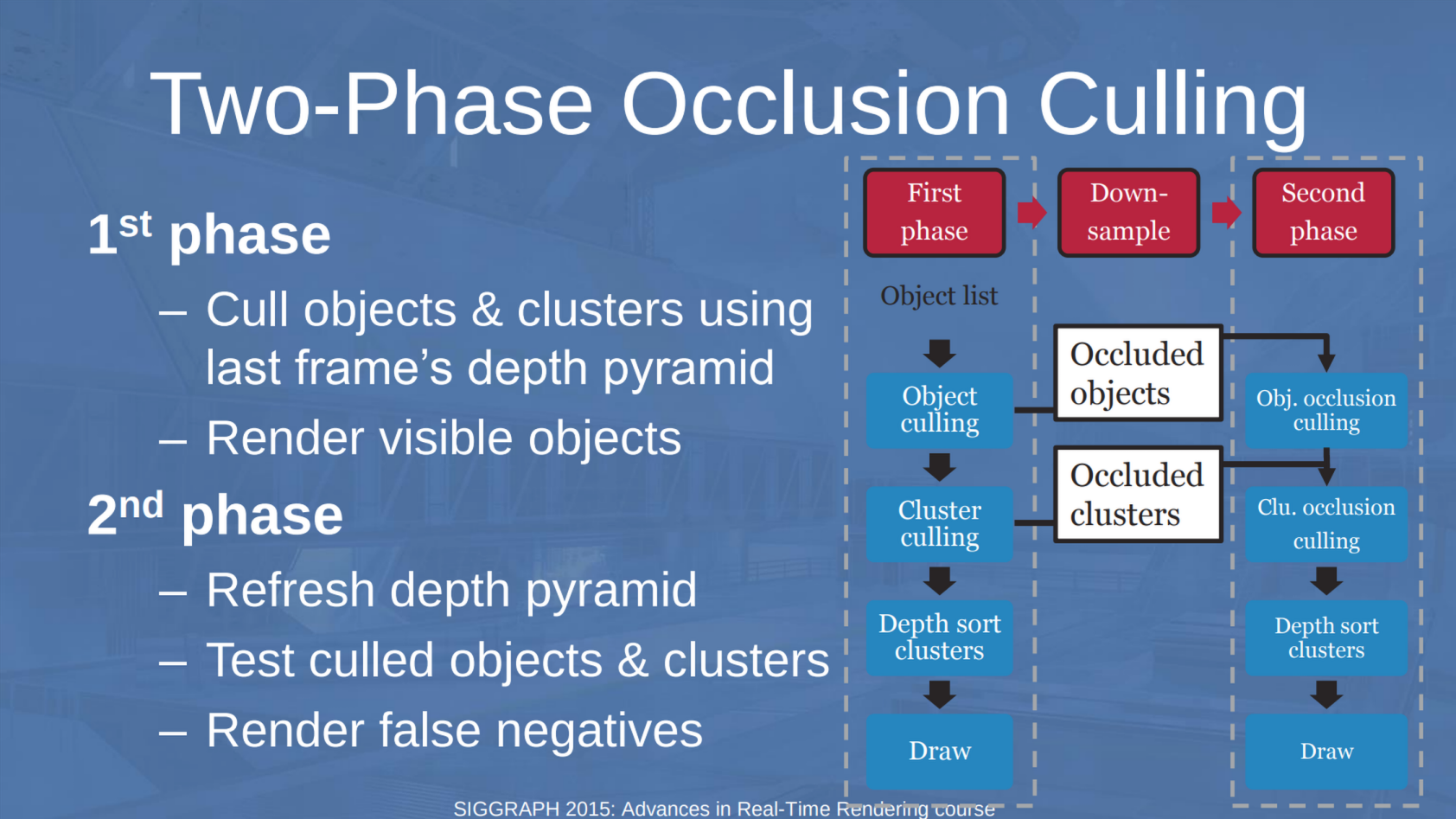
优势良多,这里不一一介绍,这里将整个场景拆成两次渲染:
- 第一次:复用上一帧得到的HZB,对通过 HZB Cull的单元(Meshlet)渲染并标记,第二次跳过这些单元。
- 第二次:第一次留下的ZBuffer值得被用于更新HZB。之后,用更新的HZB继续Cull并渲染未被标记的单元。
- 最后可选的,若后续仍有Pass需要HZB利用,在这里再次更新。
实现上细节相当,相当多;值得注意的几点有:
第二次请不要清空GBuffer/ZBuffer - -
AABB投影还请参见第一篇提及内容。这里利用的是 Approximate projected bounds - Arseny Kapoulkine的实现;注意clip znear者直接pass(通过剔除)。**注意:**原文NDC到UV的转换是在Vulkan默认NDC进行的,而我们已经做了Y flip转换。同时我们相机看的是$-Z$ - 这里需要注意最后xyzw调配和符号。
// 2D Polyhedral Bounds of a Clipped, Perspective-Projected 3D Sphere. Michael Mara, Morgan McGuire. 2013 // Returns (x1, y1, x2, y2) in UV space [0,1] from OpenGL NDC space bool projSphereAABB(float3 c /* view */, float r /* scaled */, float P00, float P11, float zNear, out float4 aabb) { // f = 1 / tan(fovY / 2), a = aspect ratio // P00 = f/a, P11 = f if (c.z + r > -zNear) // clipping near plane return false; float3 cr = c * r; float czr2 = c.z * c.z - r * r; float vx = sqrt(c.x * c.x + czr2); float minx = (vx * c.x - cr.z) / (vx * c.z + cr.x); float maxx = (vx * c.x + cr.z) / (vx * c.z - cr.x); float vy = sqrt(c.y * c.y + czr2); float miny = (vy * c.y - cr.z) / (vy * c.z + cr.y); float maxy = (vy * c.y + cr.z) / (vy * c.z - cr.y); aabb = float4(minx * P00, miny * P11, maxx * P00, maxy * P11); aabb = aabb.zyxw * float4(-0.5f, 0.5f, -0.5f, 0.5f) + float4(0.5f); // OGL clip space -> uv space return true; }两次pass遍历的meshlet单元是一样的(至少我的实现如此)。因此标记buffer可以选择不去刻意清空而选择
bitmask & (~(1u << bit))置0,不过清空也很快。假阴性(剔除过少)是不可避免的。但是假阳性(剔除过多)一定是你的实现有误——最长边像素大小请务必取得保守:比如niagara就采用了下取整到$2^n$的zbuffer大小做像素大小上界。
Shader 核心部分参下:
// -- Occlusion Cull --
uint32_t meshletGlobalID = mesh.meshletGlobalIndex + meshletID;
if (cullOcclusion && visible) {
if (late) {
bool phase1Visible = occlusion[meshletGlobalID / 32].load() & (1u << (meshletGlobalID % 32));
if (phase1Visible)
visible = false; // Skip
}
if (visible) {
float4 aabb; // x1, y1, x2, y2 in UV
// Let anything past the near plane pass
const float hizWidth = 1u << globalParams.zbufferWidthP2;
const float hizHeight = 1u << globalParams.zbufferHeightP2;
viewCenter = pointToView(meshlet.centerRadius.xyz, inst, globalParams.view);
float radius = meshlet.centerRadius.w * scale;
if (projSphereAABB(viewCenter, radius, globalParams.proj[0][0], globalParams.proj[1][1], globalParams.zNear, aabb)) {
float width = hizWidth * (aabb.z - aabb.x);
float height = hizHeight * (aabb.w - aabb.y);
float l = max(width,height);
float lambda = min(floor(log2(max(l, 1.0f))), globalParams.hizLevels - 1.0f);
float2 texel = (aabb.xy + aabb.zw) / 2.0f;
float d = hiz.SampleLevel(hizSampler, texel, lambda).x;
// View space depth *decreases* with distance
float viewDepth = viewCenter.z + radius;
float dMax = globalParams.zNear / -viewDepth;
bool pass = d <= dMax;
visible &= pass;
// Commit to occlusion buffer if visible ONLY in early pass
if (early) {
if (visible)
occlusion[meshletGlobalID / 32].or(1u << (meshletGlobalID % 32));
}
}
}
}
效果
如图,可见场景中被窗帘遮盖的维纳斯在开启后被成功剔除,Overdraw内不可见。
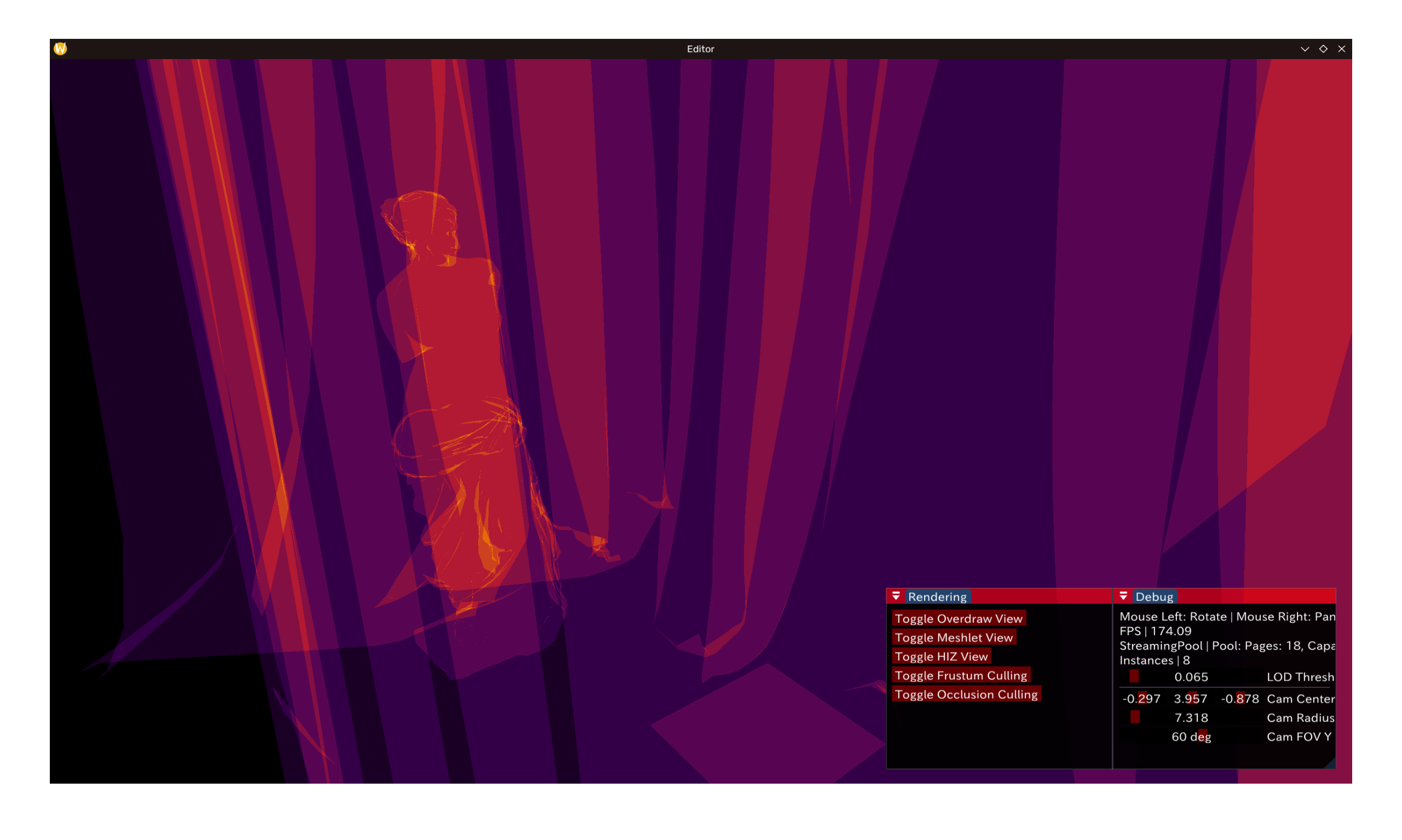
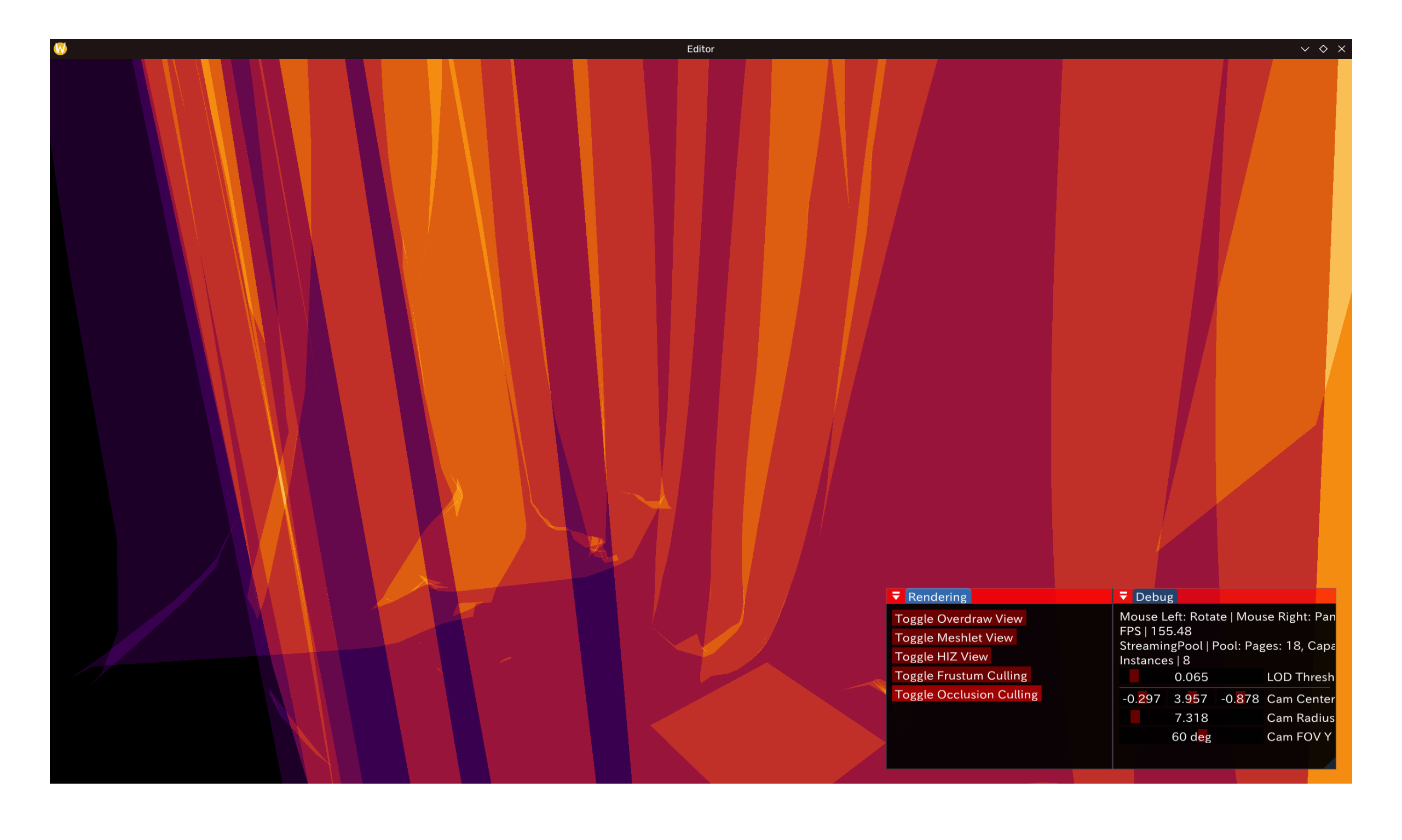
值得注意的是这里显然的假阴性:中间的一块正方形就没能被剔除掉。原因很显然,球体bounding box对大多数网格而言会是非常保守的——平面则是该类bbox的worst case。相反,对精细度高(如维纳斯)的网格,meshlet很小,在此效果更加显著。以下为 GLTF 样例模型 Sponza 的剔除效果(前/后):
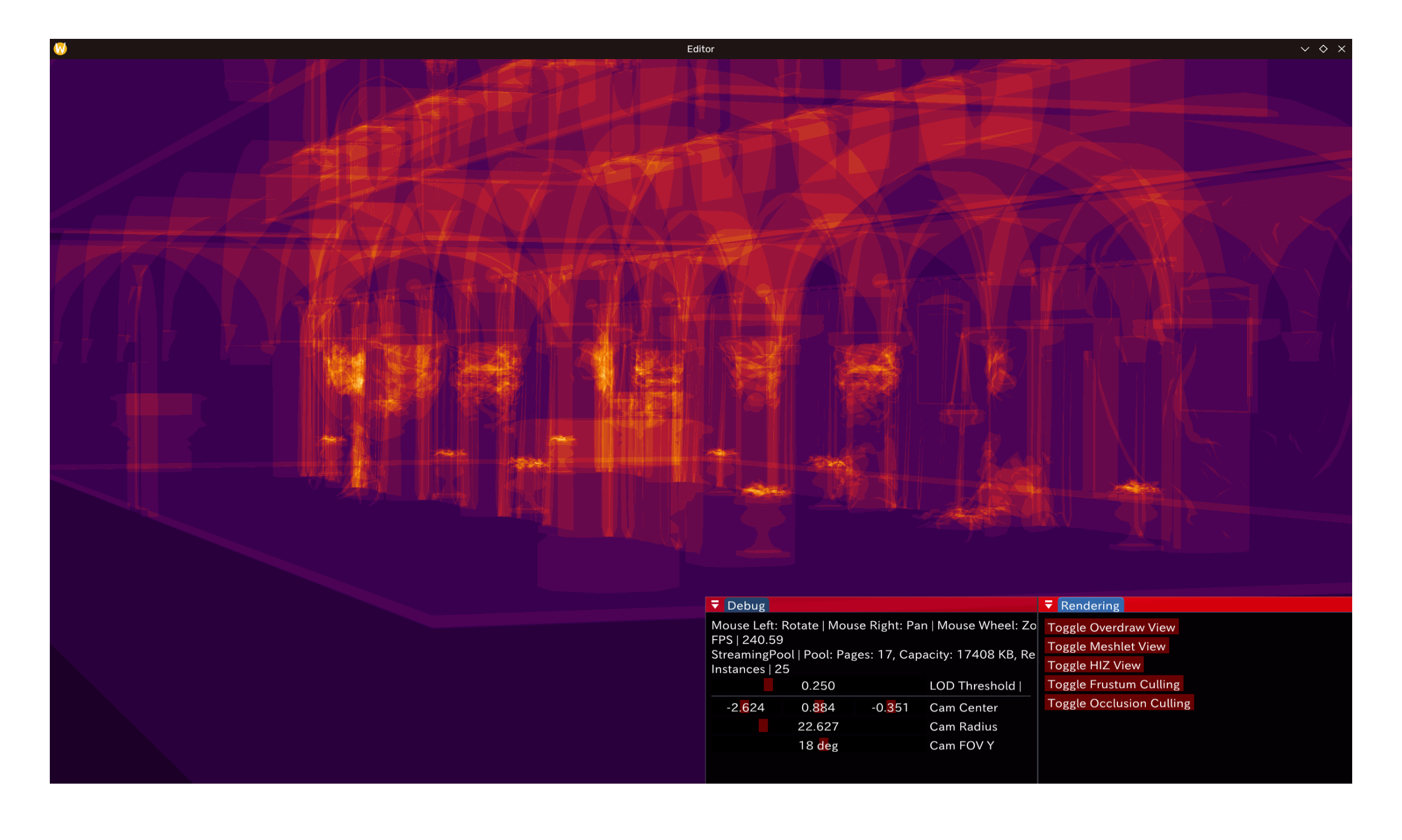
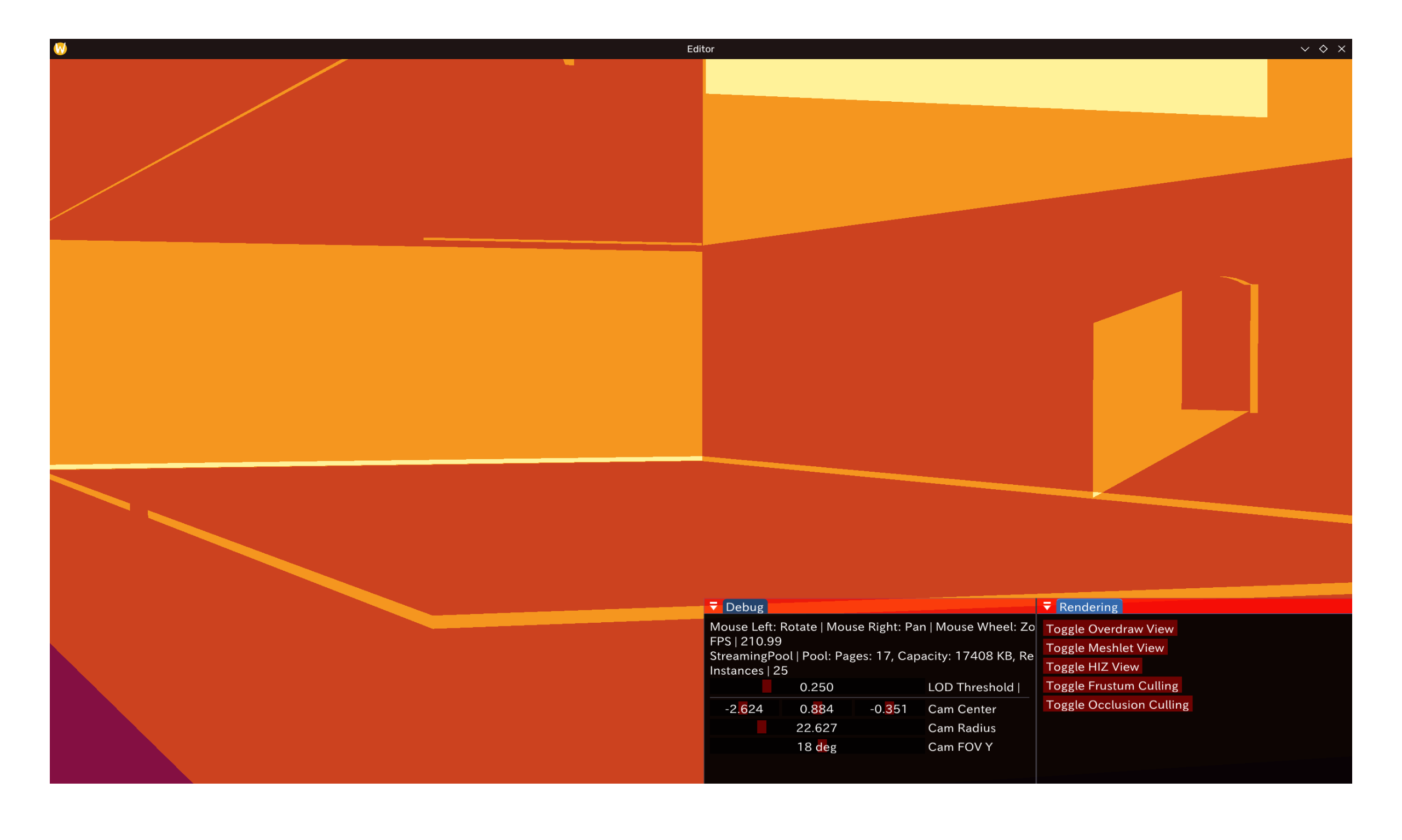
圆锥及背面剔除(Cone/Backface Culling)
Cone Culling 部分来自meshoptimizer,以下为引用:
The resulting
boundsvalues can be used to perform frustum or occlusion culling using the bounding sphere, or cone culling using the cone axis/angle (which will reject the entire meshlet if all triangles are guaranteed to be back-facing from the camera point of view):if (dot(normalize(cone_apex - camera_position), cone_axis) >= cone_cutoff) reject();Cluster culling should ideally run at a lower frequency than mesh shading, either using amplification/task shaders, or using a separate compute dispatch.
视角与预计算圆锥法线角度超过该阈值即可认为所有meshlet内三角形背面而直接剔除,同时这里对所有三角形而言是充要的。Task shader中实现即可。
接下来在Mesh Shader环节,我们还可以进行逐三角形的背面剔除/Backface Culling:假设环绕方向逆时针,利用生成的三角形两边叉乘符号即可判断是否backface,设置SV_CullPrimitive决定剔除:这里是可以取代光栅器的cull mode的,不过读取变换后顶点也会产生一定开销,故暂时没有加入实现。
效果图略。