Preface
预谋多时而虽迟但到的 Foundation 博文系列。
特别中二的名字以外,项(天)目(坑)并非最近开始的工作(开始于约莫 ~2023)。期间诸多内容,如各类无锁 (Lock-free) 数据结构、RHI、RenderGraph细节、Shader 反射等,也都是实现期间相当想留一笔的工作…
嘛、反正也是后期也不得不记的事,不如梭哈开篇为好——那么就开始吧?
注: Foundation 文档:https://mos9527.com/Foundation/
Mesh Shader?
注: 参考性内容 - 酌情跳过。 深入了解,还请参阅以下文档:
- Introduction to Turing Mesh Shaders - NVIDIA
- 【技术精讲】AMD RDNA™ 显卡上的Mesh Shaders(一): 从 vertex shader 到 mesh shader
脱离 Fixed Function 的整套Input Assembler/Vertex+Geometry管线,繁而就简:Fragment/Pixel之前,Compute模式的Mes 足矣且充分地代替这些功能。
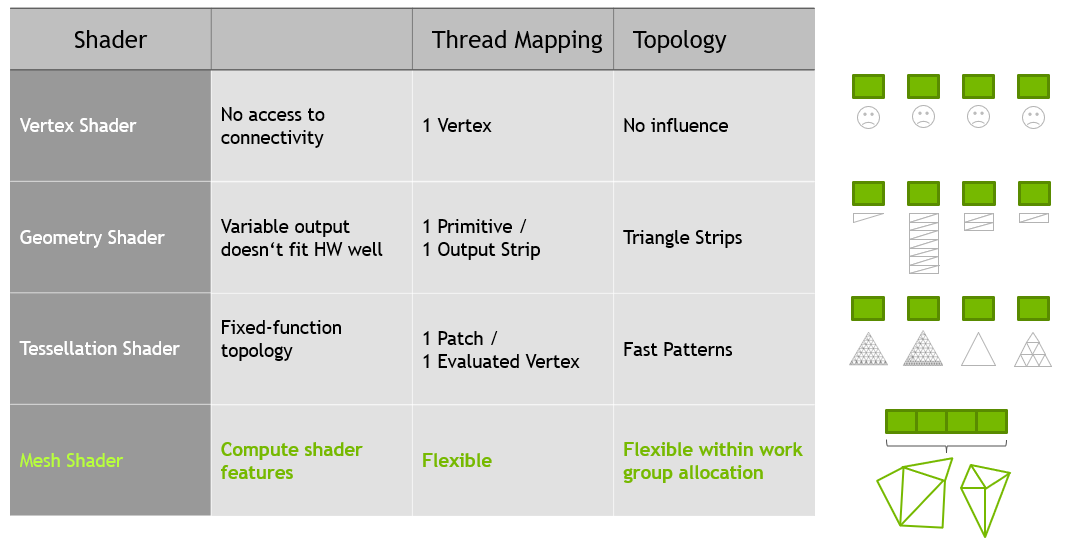
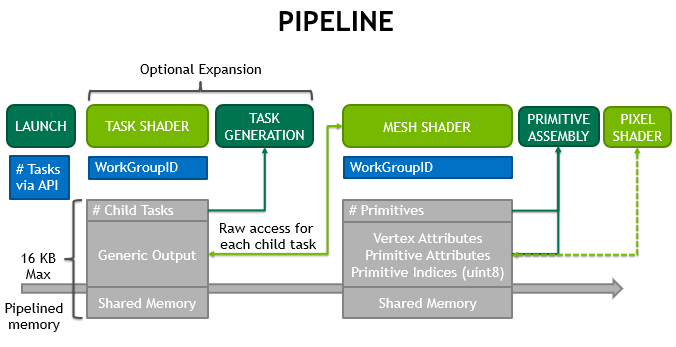
额外的,前置还可以有Task/Amplification环节生成 Mesh Shader WorkGroup(同时,Task Shader 也支持 Indirect Dispatch)。很显然,这样的架构是相当适合当代 GPU-Driven 渲染器的实现的。
最小单元(Primitive)仍然还是三角形 - 为饱和CS单元利用率,Mesh Shader同时引入了Meshlet - 依据一定指标对Mesh进行分区 - 直接地减小overhead, 间接的提供压缩(index buffer压到N个micro buffer/uint8),剔除机会,和…
Enter Nanite
作为 UE5 的招牌特性,Nanite 利用新管线的高粒度与可控性实现了消除 LOD 过渡的任务。

除此之外,其实现对流送/Streaming的支持也实现了虚拟几何体而无视显存限制等等的优良特性,免费镶嵌/Tesselation,和对极高面数的网格支持,免去Batching/Instancing…
最先产品化这类技术的,最早考证可追溯于GPU-Driven Rendering Pipelines - Sebastian Aaltonen SIGGRAPH 2015。同时,业内,包括 Unity / 团结引擎 - 虚拟几何体, RE Engine - Is Rendering Still Evolving? ,Remedy Northlight - Alan Wake 2: A Deep Dive into Path Tracing Technology,及业余空间中的 bevy 等等也已在自己的管线实现了类似的技术。

又炫又高效…那给自己的玩具渲染器实现的理由,岂不是已经超级充分?
Hello Meshlets
现在,后退几步。即使不做 LOD,你的Meshlet怎么而来?
回顾前文 - Meshlet的本质是网格顶点的分区。从无向,联通(假设凸包)的几何体面上拆下面来…事实上,正是一个最小割/图分区问题。

以某种指标出发,将整张由网格顶点构成的图分割成N份,优化这个指标…
当然,这里可没有源点汇点,不能归纳为费用流一类问题。事实上,这类问题属于 NP 难范畴。多项式时间内可解决的方案也均为启发式。如 Nanite paper 中提及的 METIS - 用于后文阐述 Meshlet 建图,但同时也适用 Meshlet 自身生成。
实现上,自己选择了 - zeux/meshoptimizer。实不相瞒,这个库的存在可以说是是整篇文章存在的理由(拜谢 Arseny!)
(还记得使用初期发现的一个文档方面小 Issue…有被大佬响应的及时程度震撼到)
实现
利用meshoptimizer划分 Meshlet 本身相当容易。以下为实现部分节选。
注意以下关系成立:outMeshletVertices[outMeshletTriangles[u]] = indices[v], 即每个Meshlet都含一个"微型"Index Buffer。同时注意到,存储outMeshletTriangles仅需对应每个Meshlet有限的顶点(<256个),存储时即使用uint_8。
...
size_t maxMeshlets = meshopt_buildMeshletsBound(indices.size(), kMeshletMaxVertices, kMeshletMaxTriangles);
// Worst bounds
outMeshletVertices.resize(maxMeshlets * kMeshletMaxVertices), outMeshletTriangles.resize(maxMeshlets * kMeshletMaxTriangles);
Vector<meshopt_Meshlet> meshoptMeshlets(maxMeshlets, outMeshlet.get_allocator());
size_t meshlets =
meshopt_buildMeshlets(meshoptMeshlets.data(), outMeshletVertices.data(), outMeshletTriangles.data(),
indices.data(), indices.size(), reinterpret_cast<const float*>(&vertices[0]),
vertices.size(), sizeof(Vertex), kMeshletMaxVertices, kMeshletMaxTriangles,
0.25f // As recommended by the docs
);
meshoptMeshlets.resize(meshlets);
{
const auto& [vertexOffset, triangleOffset, vertexCount, triangleCount] = meshoptMeshlets.back();
outMeshletVertices.resize(vertexOffset + vertexCount);
outMeshletTriangles.resize(triangleOffset + triangleCount * 3);
}
...
渲染部分,简单起见 - 直接使用单个 Mesh Shader 与 DrawMeshTasks (对应 vkDrawMeshTasksEXT) 命令足矣。Dispatch数目即为Meshlet数目,即一个 WorkGroup 对应一个 Meshlet
Foundation 内的实现如下。详见 https://github.com/mos9527/Foundation/blob/vulkan/Examples/MeshShaderBasic.cpp
...
renderer->CreatePass(
"Mesh Shader", RHIDeviceQueueType::Graphics, 0u,
[=](PassHandle self, Renderer* r)
{
r->BindBackbufferRTV(self);
r->BindTextureDSV(self, zbufferHandle,
{.format = RHIResourceFormat::D32SignedFloat,
.range = RHITextureSubresourceRange::Create(RHITextureAspectFlagBits::Depth)});
r->BindShader(self, RHIShaderStageBits::Mesh, "meshMain", "data/shaders/MeshShaderBasicMesh.spv");
r->BindShader(self, RHIShaderStageBits::Fragment, "fragMain", "data/shaders/MeshShaderBasicFrag.spv");
// NOTE: globalParams is introduced by slang compiler and is currently not customizable
// for uniform storage members
r->BindBufferUniform(self, uboHandle, RHIPipelineStageBits::MeshShader, "globalParams");
r->BindBufferStorageRead(self, meshHandle,
RHIPipelineStageBits::MeshShader | RHIPipelineStageBits::FragmentShader, "mesh");
},
[&](PassHandle self, Renderer* r, RHICommandList* cmd)
{
auto const& img_wh = r->GetSwapchainExtent();
auto* uboData = r->DerefResource(uboHandle).Get<RHIBuffer*>();
cmd->UpdateBuffer(uboData, 0, AsBytes(ubo));
r->CmdBeginGraphics(self, cmd, img_wh);
r->CmdSetPipeline(self, cmd);
// Simplest dispatch - spawn meshlets one by one to each Mesh Shader WG
// We don't need a task shader - if unbound, DrawMeshTasks dispatches
// Mesh Shader workgroups effectively directly.
cmd->SetViewport(0, 0, img_wh.x, img_wh.y)
.SetScissor(0, 0, img_wh.x, img_wh.y)
.DrawMeshTasks(ubo.mesh.lod[0].meshletCount, 1, 1)
.EndGraphics();
});
Shader 部分也将省略剔除等步骤 - 注意 Slang Shader 中对应 HLSL 的一些语义:
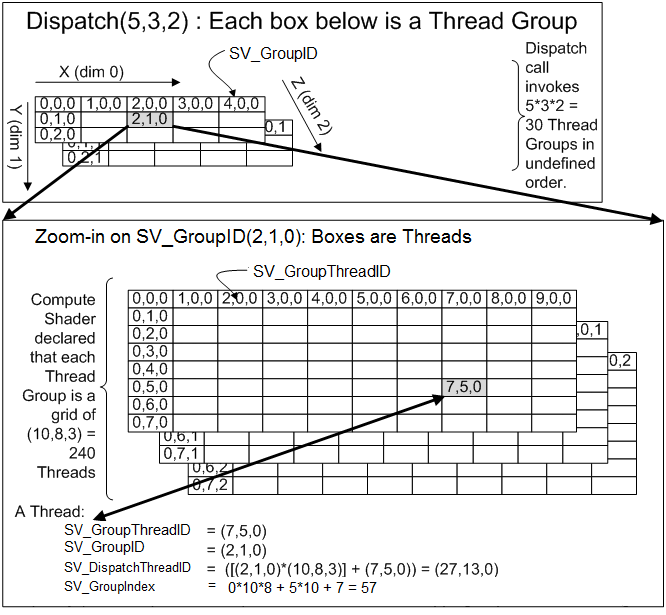
注意 Work Group 和 Meshlet 在此有一对一的关系。但同时这不意味着一个 Thread 仅对应一个顶点/三角形:参见 uint i = tid; i < vtxCount; i += kWGSize 部分。
static const size_t kWGSize = 64;
[outputtopology("triangle")]
[numthreads(kWGSize, 1, 1)]
void meshMain(
// See graphics reference available at:
// * https://learn.microsoft.com/en-us/windows/win32/direct3dhlsl/sv-groupindex
in uint gid: SV_GroupID,
in uint tid: SV_GroupIndex,
OutputVertices<V2F, 96> verts,
OutputIndices<uint3, 96> triangles,
) {
GSMeshLOD lod = globalParams.mesh.lod[0];
// Each WG of mesh shader processes *exactly* one meshlet per dispatch
FMeshlet meshlet = mesh.Load<FMeshlet>(lod.meshletOffset + gid * sizeof(FMeshlet));
uint32_t vtxBase = lod.meshletVtxOffset + meshlet.vtxOffset * sizeof(uint32_t);
uint32_t vtxCount = meshlet.vtxCount;
uint32_t triBase = lod.meshletTriOffset + meshlet.triOffset * sizeof(uint8_t);
uint32_t triCount = meshlet.triCount;
SetMeshOutputCounts(vtxCount, triCount);
// Each thread in the WG processes multiple vertices/triangles
for (uint i = tid; i < vtxCount; i += kWGSize) {
uint ind = mesh.Load<uint32_t>(vtxBase + i * sizeof(uint32_t));
FVertex vtx = mesh.Load<FVertex>(globalParams.mesh.vtxOffset + ind * sizeof(FVertex));
V2F v2f;
v2f.pos = mul(globalParams.mvp, float4(vtx.position, 1.0));
v2f.meshlet = gid;
verts[i] = v2f;
}
for (uint i = tid; i < triCount; i += kWGSize) {
MIndex tri = mesh.Load<MIndex>(triBase + i * sizeof(MIndex));
triangles[i] = uint3(tri.v0, tri.v1, tri.v2);
}
}
Fragment部分直接显示各Meshlet编号。哈希函数来自 https://github.com/zeux/niagara/
struct V2F
{
float4 pos : SV_POSITION;
uint32_t meshlet : ID;
};
uint hash(uint a)
{
a = (a + 0x7ed55d16) + (a << 12);
a = (a ^ 0xc761c23c) ^ (a >> 19);
a = (a + 0x165667b1) + (a << 5);
a = (a + 0xd3a2646c) ^ (a << 9);
a = (a + 0xfd7046c5) + (a << 3);
a = (a ^ 0xb55a4f09) ^ (a >> 16);
return a;
}
float3 hash3(uint a){
a = hash(a);
return float3(float(a & 255), float((a >> 8) & 255), float((a >> 16) & 255)) / 255.0;
}
struct Fragment
{
float4 color : SV_Target;
};
[shader("fragment")]
Fragment fragMain(V2F input)
{
Fragment output;
output.color = float4(hash3(input.meshlet), 1.0);
return output;
}
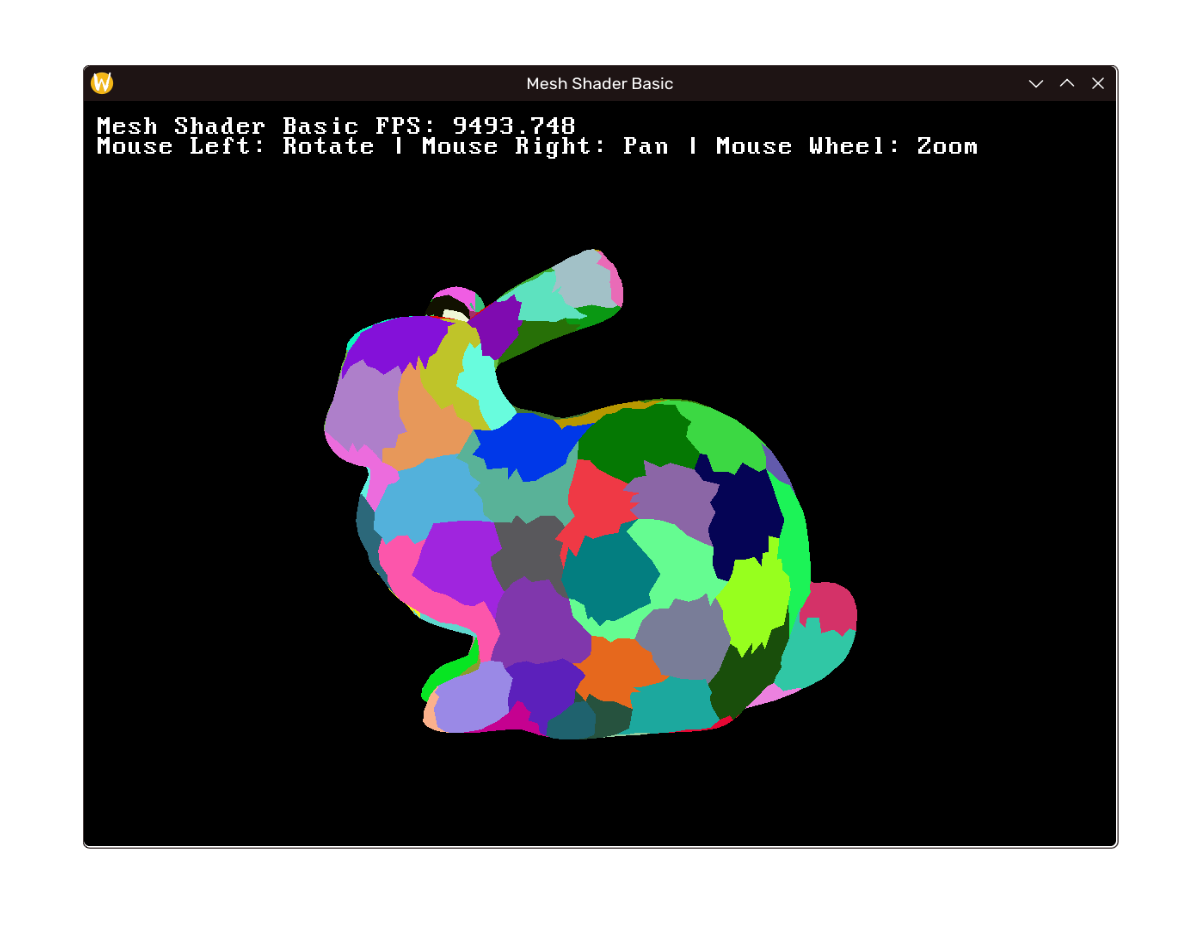
载入斯坦福小兔兔。效果如图。
LOD Group
接下来,就 Nanite - A Deep Dive LOD 建图部分进行实现。

借论文原图 - 这里的任务即为
- 选择某些区块(可以是三角面本身,也可以是已经划分的cluster)
- 合并并简化这些区块。简化任务即与传统 LOD 生成一致,同样也是相当邪门的话题…
- 锁定分界部分并分割。锁定为避免不同LOD边界过渡不平滑;分割如选4分2,即可构造下一级LOD
- 区分下来的这些区块均为区分原cluster的子节点
最后,重复到只剩一级LOD为止,即到达根节点。
对分组任务,是否很熟悉?没错 - 这里同样也是一个图划分任务。只不过多了需要迭代+锁边的需求。

实现
自己研究初期,Arseny (meshoptimizer 作者) 正好发布了这篇博文: Billions of triangles in minutes - zeux.io
除了极大程度地避免自己走弯路以外,作者同期也将自己的 LOD 建图实现分离并给予 API 食用 - clusterlod.h - meshoptimizer
官方 Demo 并未给出实时渲染实现。不过,LOD 建图部分可谓相当完善且好用 - 集成可谓轻而易举。
Cluster 构造
注: 个人实现 - 非官方。有误还有烦请指正!
首先,我们给Meshlet/Cluster分组。加入group表示其隶属的组编号,refined表示产生当前cluster(更精细的)组的编号
struct FMeshlet // @ref meshopt_Meshlet
{
/* meshlet group */
/* ID of the @ref FLODGroup this meshlet belongs to in a hierarchy */
uint32_t group;
/* ID of the @ref FLODGroup (with more triangles) that produced this meshlet during simplification (parent). ~0u if original geometry */
uint32_t refined;
/* meshlet */
/* offsets within meshletVtx and meshletTri arrays with meshlet data */
uint32_t vtxOffset; // in vertices
uint32_t triOffset; // in indices (3*triangles)
/* number of vertices and triangles used in the meshlet; data is stored in consecutive range defined by offset and
* count */
uint32_t vtxCount;
uint32_t triCount;
/* bounds */
float4 centerRadius; // (x,y,z,r)
float4 coneAxisAngle; // (x,y,z,cos(half solid angle))
float3 coneApex; // (x,y,z)
};
分组的目的即为$O(1)$决定组别内所有Meshlet是否值得渲染(满足某种错误指标,等等)。每组数据如下:
struct FLODGroup // @ref clodGroup
{
// DAG level the group was generated at
int depth;
// sphere bounds, in mesh coordinate space
float3 center;
float radius;
// combined simplification error, in mesh coordinate space
float error;
};
static_assert(sizeof(FLODGroup) == 24);
选择节点
值得注意的是,我们并没有直接地表示节点间的边。事实上这是不需要的。
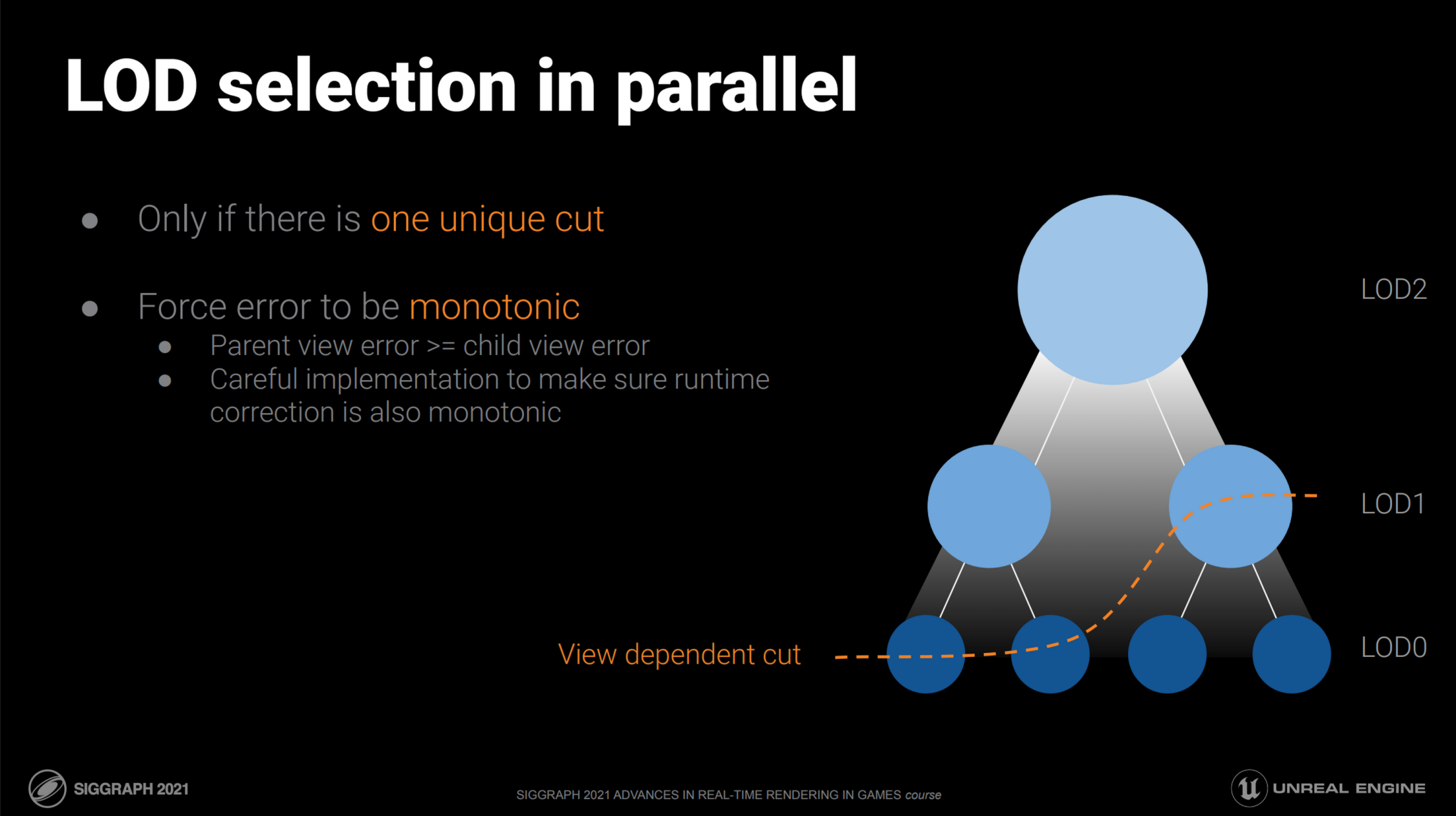
考虑渲染中我们需要做的任务:
- 选择是否渲染是检查组的错误因子是否达标。注意组越深越简化,假设(实际如此)错误系数单调递增…
- 组PASS,意味着其隶属直接子节点(一层)也被渲染,无须渲染后续组别
- 组REJECT,意味着错误系数太高,需要选择更细致组别
还记得前文我们记录了Meshlet/Cluster自己所属的组与父组吗?利用单调性,我们任意地选择一个Meshlet单元:
- 记录当前视角,当前组(
group)的错误系数为$u$,父亲组(refined)的错误系数为$v$。满足 $u \ge v$( 注: 不同于原论文,这里当前,父亲($u,v$)的关系倒置) - 选定一个阈值$t$,错误低于者PASS
- 当且仅当$u > t, v <= t$,渲染当前组
可以发现,这样可以做到选择 【且仅选择】满足阈值的【上界】的节点,找到图中"cut"所交的LOD Group,这正为我们想要的。而且很显然,这个任意操作本质并行,在Compute/Task Shader实现也将十分容易。
正式建图
DAG结构很简单,如下。
struct DAG
{
struct Cluster
{
uint32_t group{~0u}; // ID of the FLODGroup this cluster belongs to
uint32_t refined{~0u}; // ID of the FLODGroup (with more triangles) that produced this cluster during simplification (parent). ~0u if original geometry
Vector<uint32_t> indices;
Cluster(Allocator* alloc) : indices(alloc) {}
};
Vector<Cluster> clusters; // Note: scratch buffer
// -- final DAG data
Vector<FLODGroup> groups; // group error bounds
Vector<FMeshlet> meshlets; // meshlets built from all clusters
Vector<uint32_t> meshletVtx;
Vector<uint8_t> meshletTri;
DAG(Allocator* alloc) : clusters(alloc), groups(alloc), meshlets(alloc), meshletVtx(alloc), meshletTri(alloc) {}
} dag;
注意到Cluster内容是不需要上传的,因为接下来我们会利用结果直接生成Meshlet本身。建图过程如下:
clodBuild(config, mesh,
[&](clodGroup group, const clodCluster* clusters, size_t cluster_count) -> int
{
size_t group_id = dag.groups.size();
dag.groups.push_back(FLODGroup{
.depth = group.depth,
.center = {group.simplified.center[0], group.simplified.center[1], group.simplified.center[2]},
.radius = group.simplified.radius,
.error = group.simplified.error});
for (size_t i = 0; i < cluster_count; i++)
{
auto& cluster = clusters[i];
auto& lvl = dag.clusters.emplace_back(vertices.get_allocator().mResource);
lvl.group = group_id, lvl.refined = cluster.refined;
auto& ind = lvl.indices;
ind.insert(ind.end(), cluster.indices, cluster.indices + cluster.index_count);
}
return group_id; // recorded as refined IDs
});
注意到clodBuild的callback在group顺序上有单调递增的保证。最后回顾前文Meshlet构造过程,我们也就此index buffer构造micro index buffer。过程如下:
// Done - build meshlets for each cluster
size_t numIndices = 0;
for (auto& cluster : dag.clusters)
numIndices += cluster.indices.size();
// Worst bounds
dag.meshletVtx.resize(numIndices), dag.meshletTri.resize(numIndices);
uint32_t* vtx = dag.meshletVtx.data();
uint8_t* tri = dag.meshletTri.data();
dag.meshlets.reserve(dag.clusters.size());
for (auto& cluster : dag.clusters)
{
FMeshlet meshlet{
.group = cluster.group,
.refined = cluster.refined,
.vtxOffset = static_cast<uint32_t>(vtx - dag.meshletVtx.data()),
.triOffset = static_cast<uint32_t>(tri - dag.meshletTri.data()),
};
// Index to Micro Index (uint8)
size_t unique = clodLocalIndices(vtx, tri, cluster.indices.data(), cluster.indices.size());
vtx += unique, tri += cluster.indices.size();
meshlet.vtxCount = unique, meshlet.triCount = cluster.indices.size() / 3;
// Compute bounds
meshopt_Bounds bounds = meshopt_computeMeshletBounds(
&dag.meshletVtx[meshlet.vtxOffset], &dag.meshletTri[meshlet.triOffset], meshlet.triCount,
reinterpret_cast<const float*>(&vertices[0]), vertices.size(), sizeof(FVertex));
meshlet.centerRadius = float4(bounds.center[0], bounds.center[1], bounds.center[2], bounds.radius);
meshlet.coneAxisAngle =
float4(bounds.cone_axis[0], bounds.cone_axis[1], bounds.cone_axis[2], bounds.cone_cutoff);
meshlet.coneApex = float3(bounds.cone_apex[0], bounds.cone_apex[1], bounds.cone_apex[2]);
dag.meshlets.push_back(meshlet);
}
最后上传至 GPU - 详见 https://github.com/mos9527/Foundation/blob/vulkan/Examples/MeshShaderHierarchicalLOD.cpp
Discrete LOD
在实现view-dependent自动LOD之前,不妨尝试直接利用group对应的图内深度,实现传统的 LOD 过渡。
Shader 选择仅需一句话:
...
uint32_t groupBase = globalParams.mesh.groupOffset + meshlet.group * sizeof(FLODGroup);
FLODGroup lodGroup = mesh.Load<FLODGroup>(groupBase);
if (lodGroup.depth != globalParams.cutDepth) { // <- Cull depth
SetMeshOutputCounts(0, 0);
return;
}
...
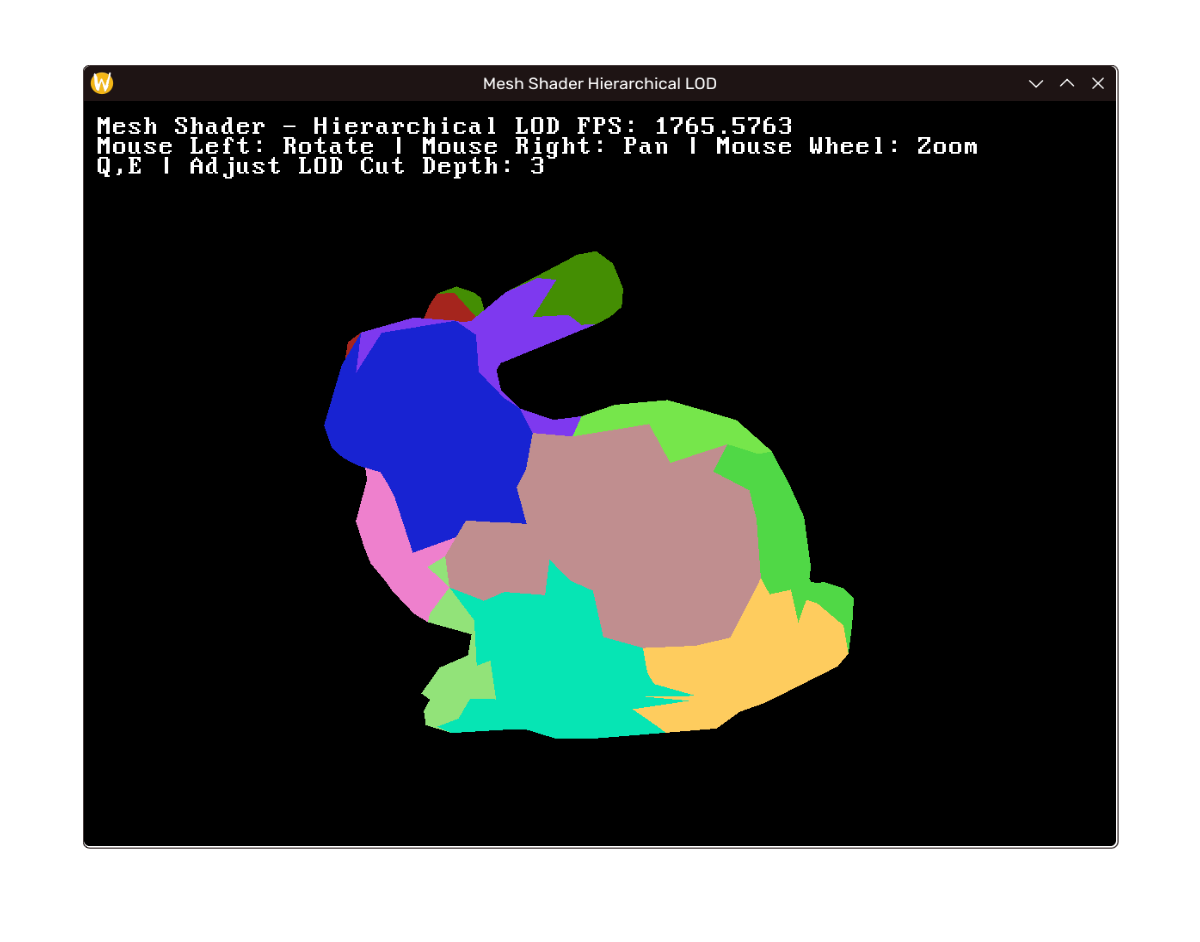
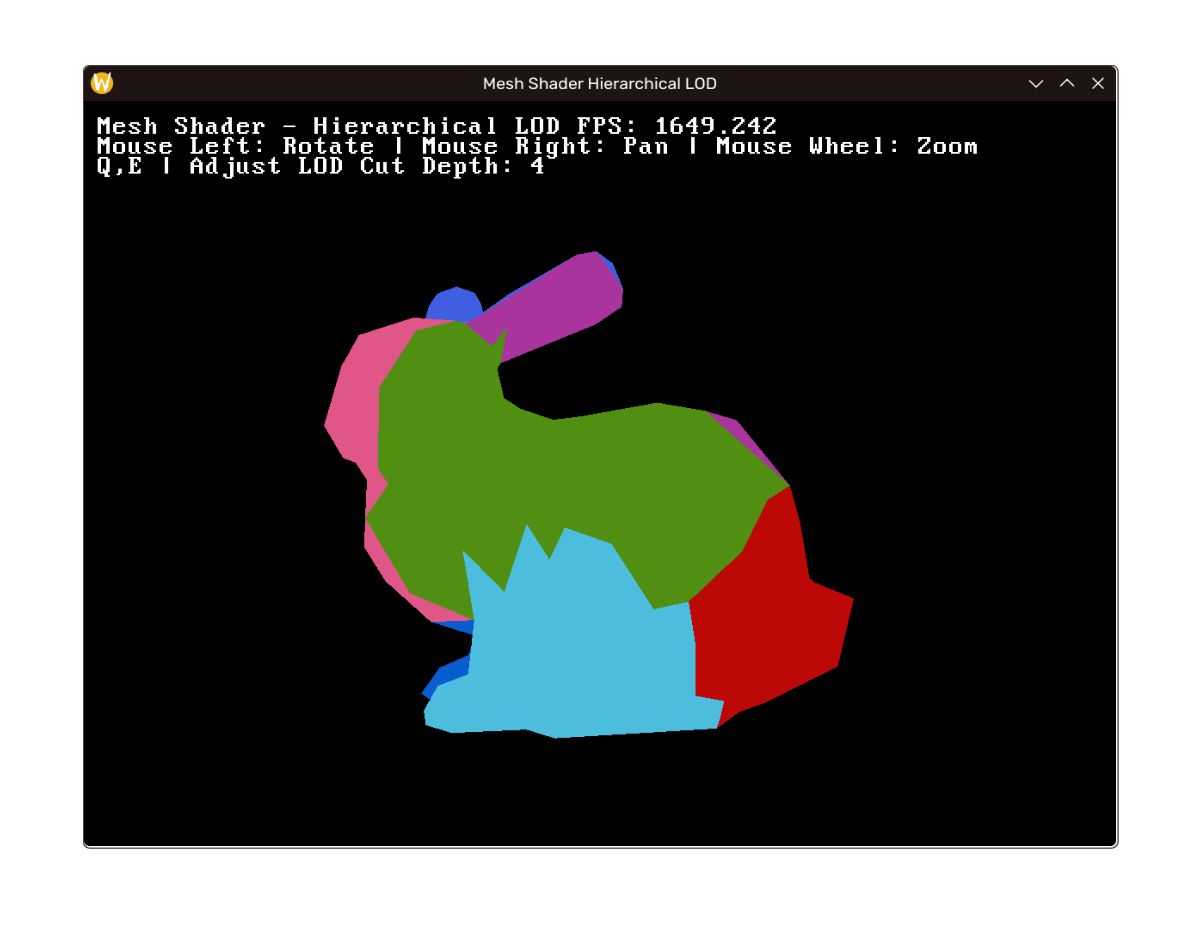
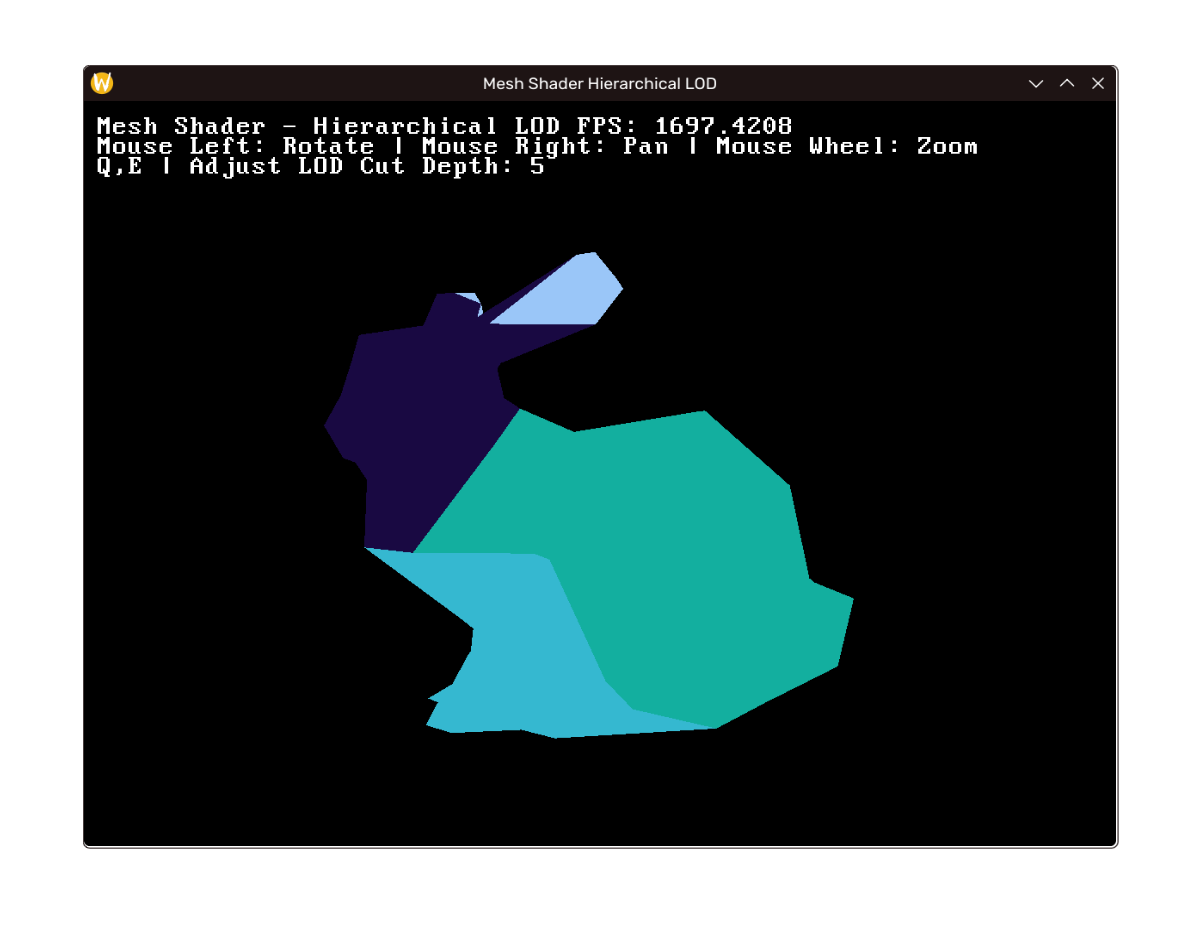
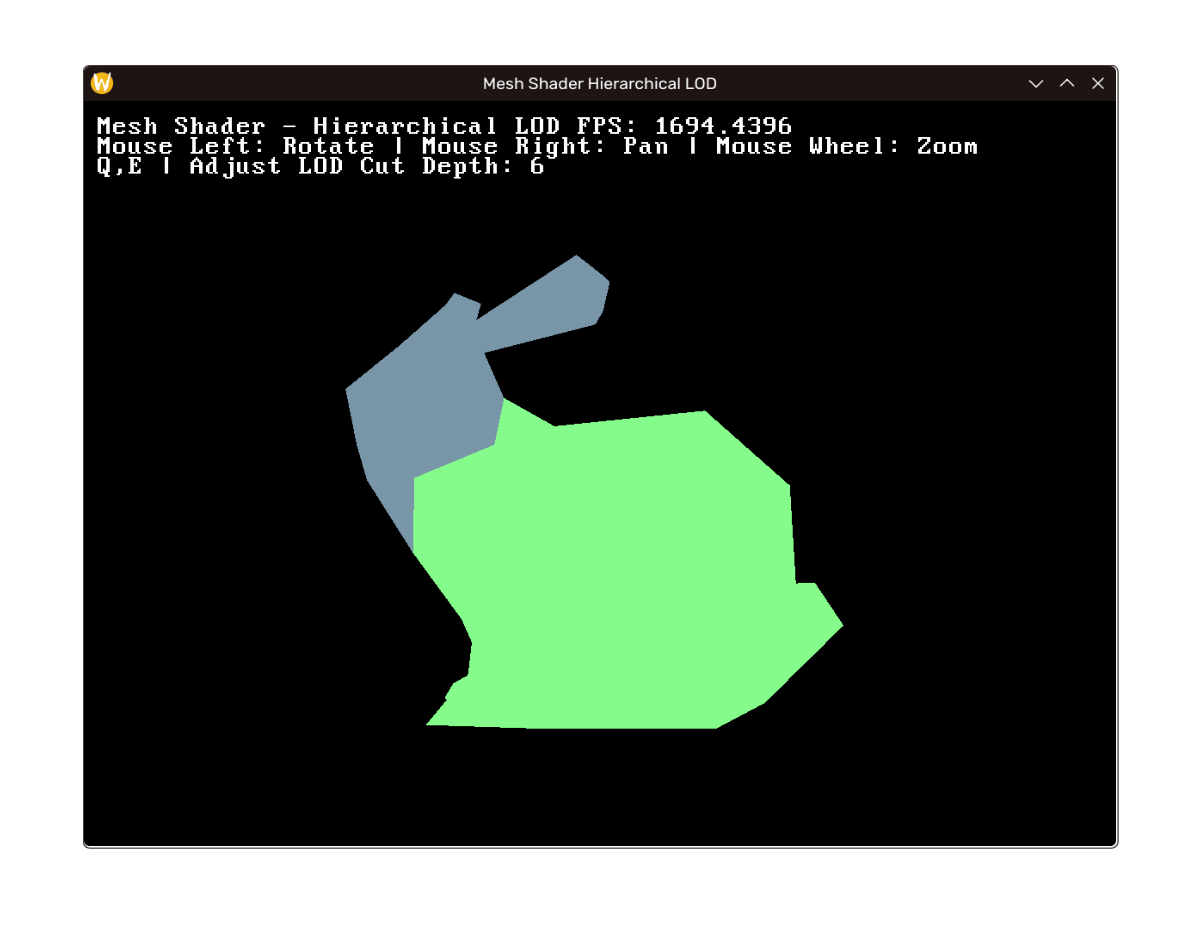
效果
效果如下,左至右上至下 LOD 层次递增。(注:帧率差距在于笔记本没插电+debug build;如未说明性能指标将实际相近)
这一部分的完整实现见: https://github.com/mos9527/Foundation/commit/c15200bbf32c8a46cb0982f5da0a7615a7c02581
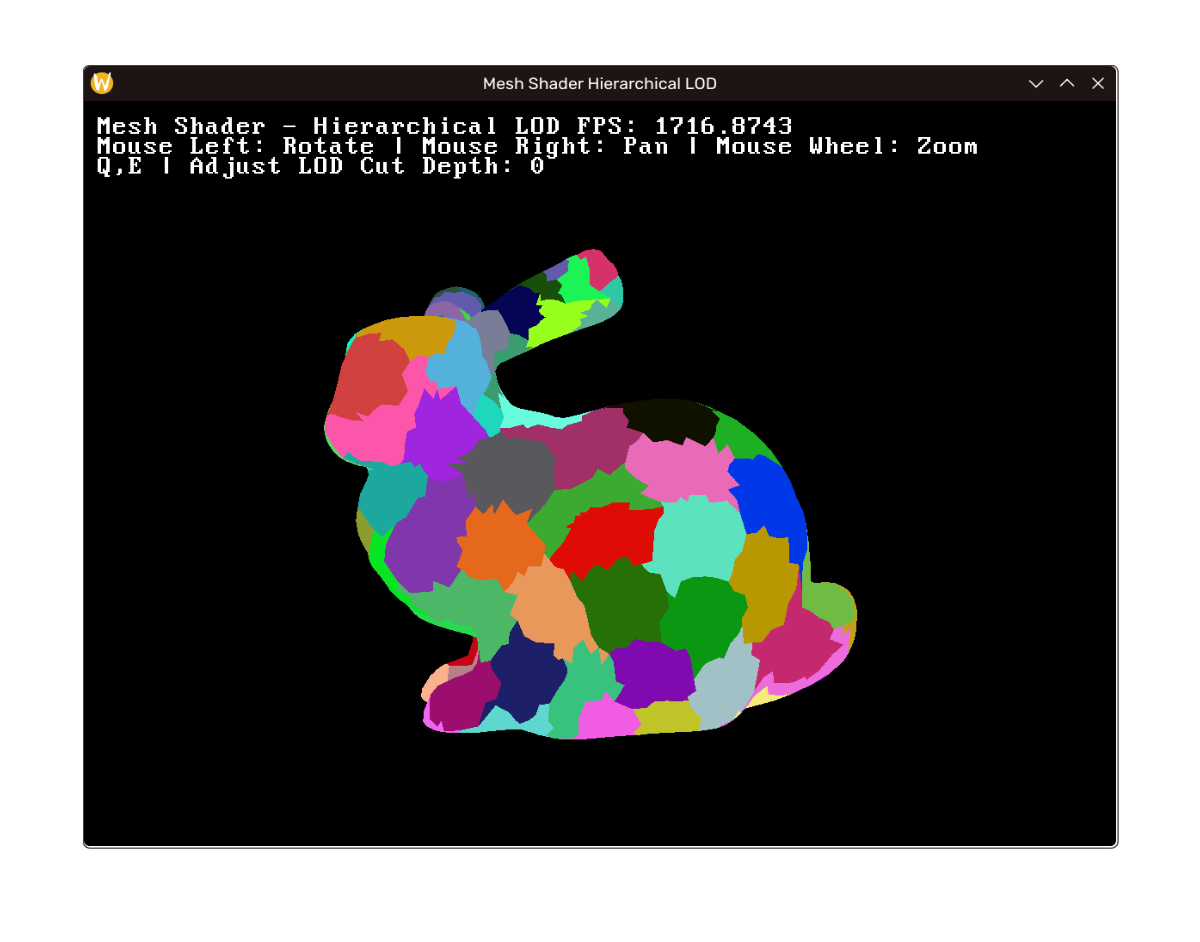 | 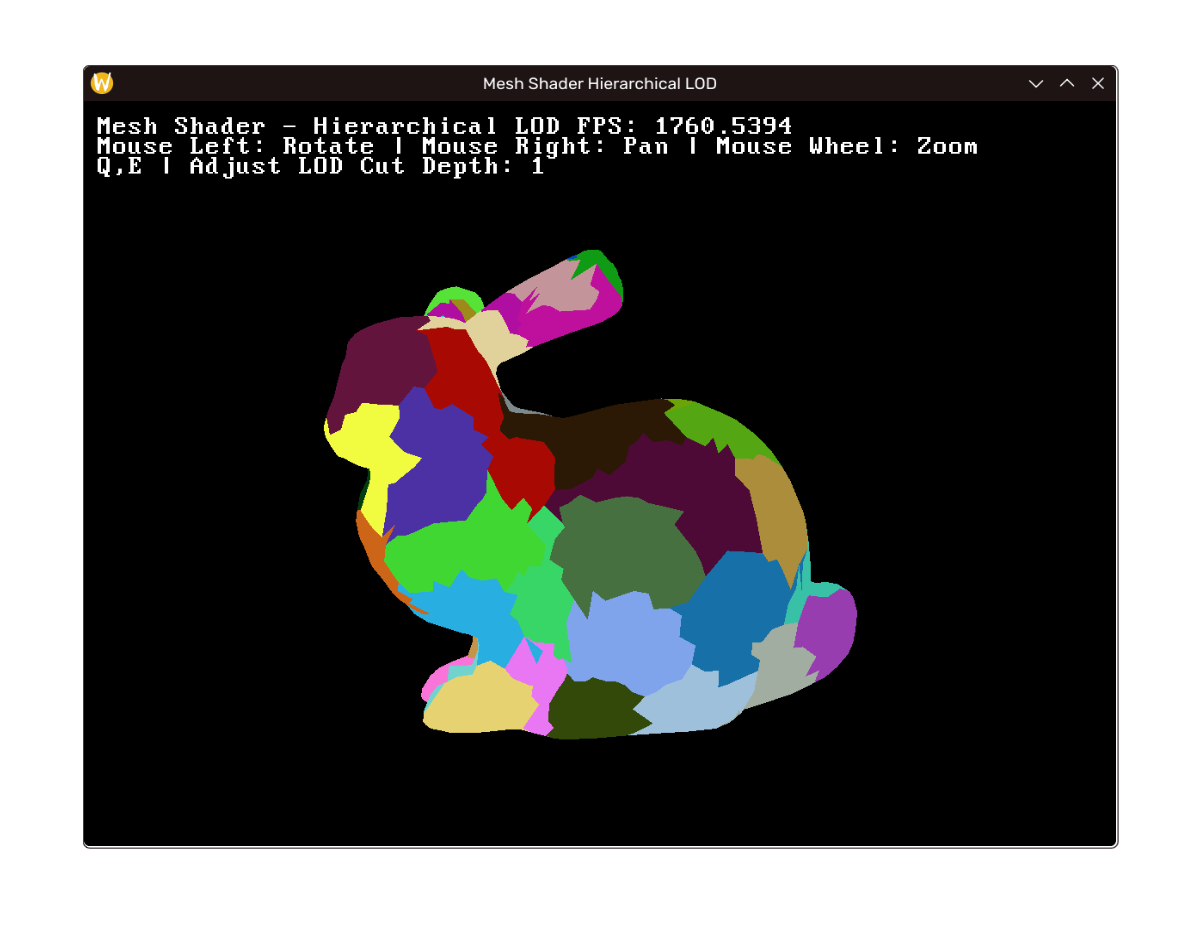 | 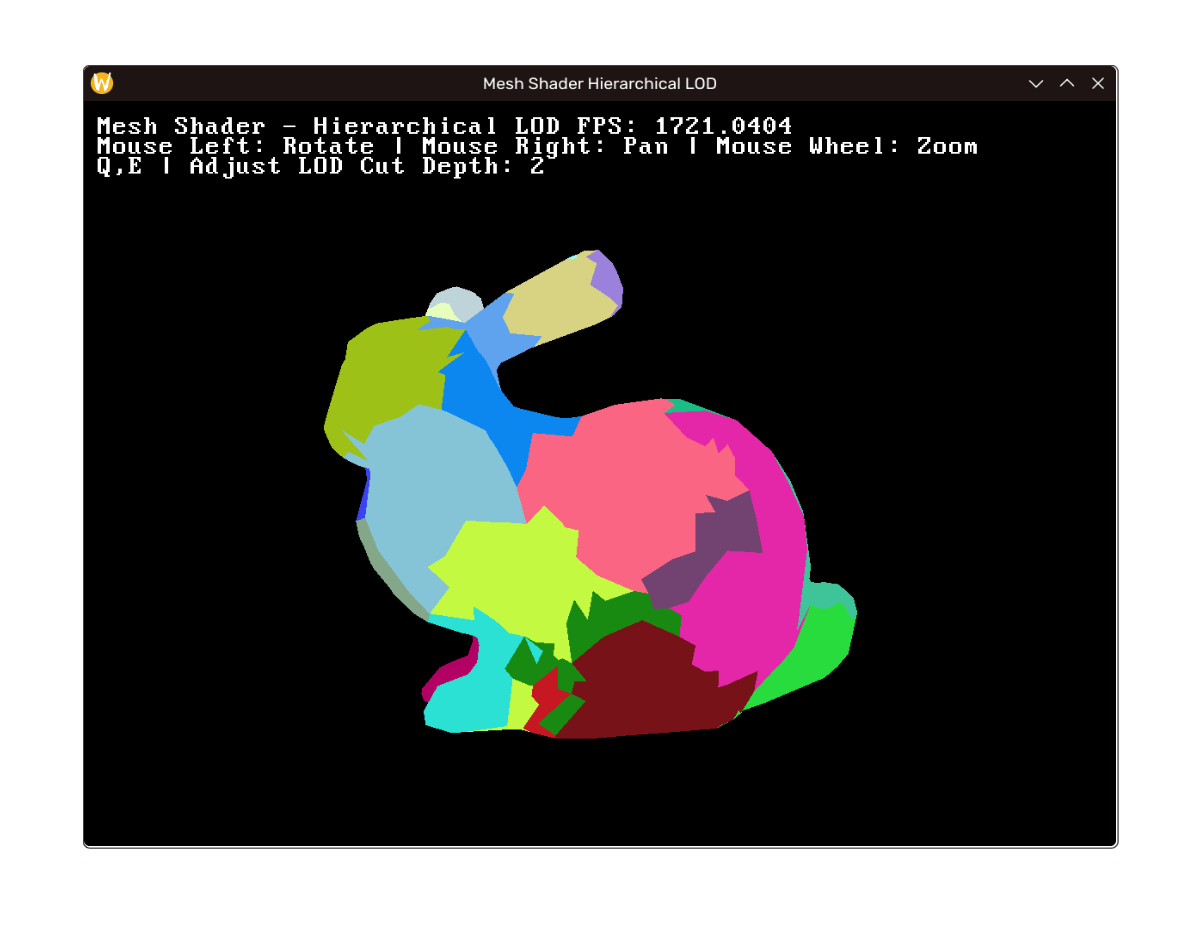 |
|---|---|---|
 |  |  |
 | 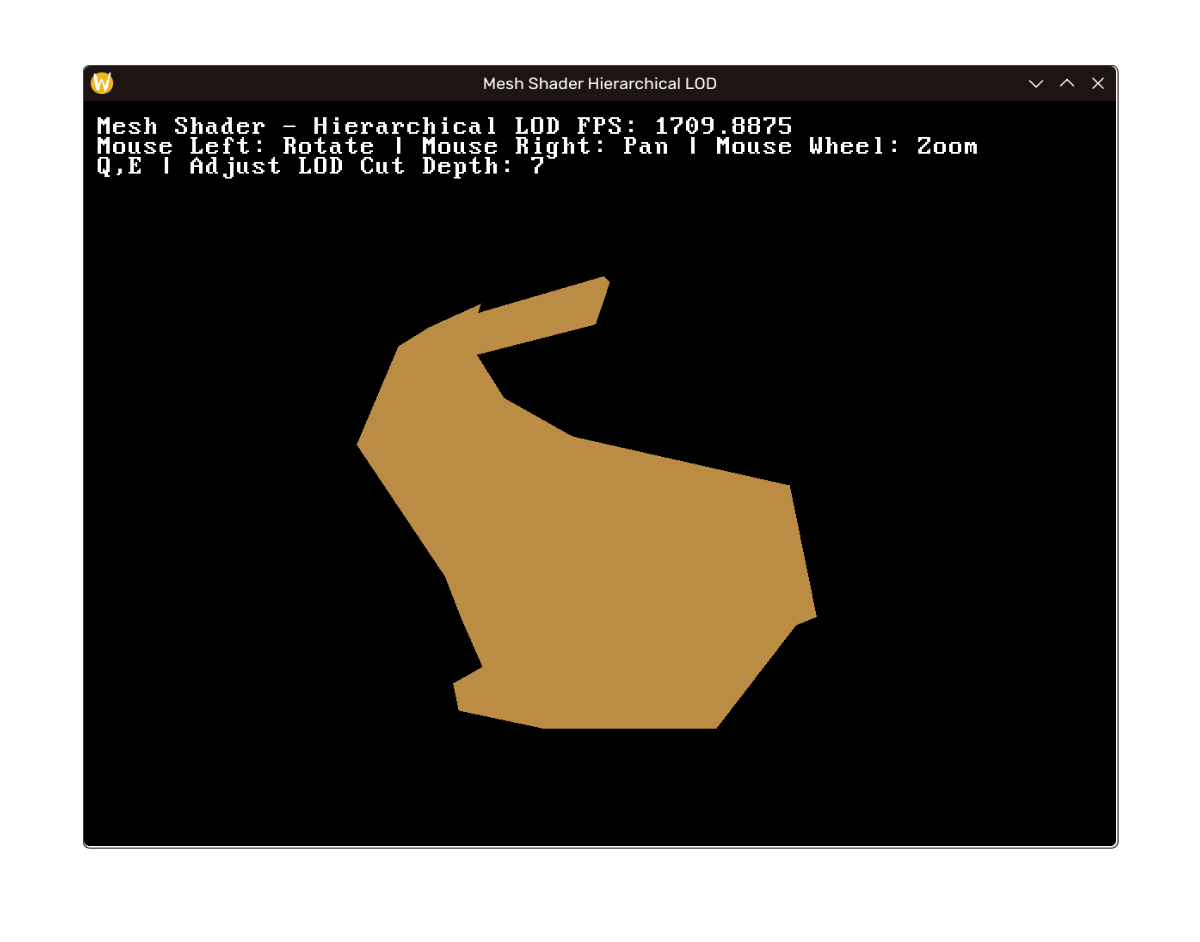 |  |
View-Dependent LOD
错误指标
对于每一个group - 我们均以得到一个以model space为空间的error系数。
当然,在渲染时需要进行缩放,表现其在screen space的‘直观影响’。直觉地,做到这一点,一是可以在屏幕空间利用其所占面积,即投影后屏幕空间bounding box大小 - 这点在后期遮蔽剔除实现中也会再次得到应用。
对于球体bbox,透视投影后的屏幕空间表现会是椭圆 。
- 2D Polyhedral Bounds of a Clipped, Perspective-Projected 3D Sphere (Michael Mara, Morgan McGuire) 提供了计算其准确屏幕空间AABB长方形的手段。
- 同时,假设不考虑物体与near平面相交(情况,计算量可以很小:这里参见 Approximate projected bounds - Arseny Kapoulkine。
- 而不幸的是,这类情况在保证
error系数单调($projected(refined)<=projected(group)$系数仍然成立)的前提下是不能不考虑的。
当然,球体屏幕空间所占大更为保守(偏大)的估计也存在。clusterlod.h demo 中就直接利用了视角倒球面最近距离在视场Y轴上投影长度来估计大小 - 这也让与near平面相交(非完全在near平面另一侧 - 此时为Y轴大小)的球体投射大小得以体现 - 实现非常简单。
float projErrorSimple(FLODGroup lodGroup) {
float3 center = mul(globalParams.view, float4(lodGroup.center, 1.0)).xyz;
float r = lodGroup.radius;
float d = max(length(center) - r, globalParams.zNear);
return lodGroup.error / d * abs(globalParams.proj[1][1]);
}
运行时 Cut
即在shader中引入前文cut阈值及屏幕空间指标。实现如下,附注还请参考注释:
...
FLODGroup selfGroup = mesh.Load<FLODGroup>(globalParams.mesh.groupOffset + meshlet.group * sizeof(FLODGroup));
float selfError = projErrorSimple(selfGroup);
// Remember - we take the upper_bound of the acceptable clusters
// where it's the *first* LOD that exceeds the error threshold
bool culled = selfError <= globalParams.threshold;
if (meshlet.refined != ~0u){
FLODGroup refGroup = mesh.Load<FLODGroup>(globalParams.mesh.groupOffset + meshlet.refined * sizeof(FLODGroup));
float refError = projErrorSimple(refGroup);
// The refined ones exceeds it too - impossible unless it's closer to
// the actual upper bound. So cull ourselves.
culled |= refError > globalParams.threshold;
}
// If culled do not render
...
效果
以上实现详见 https://github.com/mos9527/Foundation/commit/087d269599a6fbfc6056f708cea21a3dad8f2806
References
- Foundation
- Foundation 文档
- Introduction to Turing Mesh Shaders - NVIDIA
- 【技术精讲】AMD RDNA™ 显卡上的Mesh Shaders(一): 从 vertex shader 到 mesh shader
- GPU-Driven Rendering Pipelines - Sebastian Aaltonen SIGGRAPH 2015
- Unity / 团结引擎 - 虚拟几何体
- RE Engine - Is Rendering Still Evolving?
- Remedy Northlight - Alan Wake 2: A Deep Dive into Path Tracing Technology
- bevy
- METIS
- zeux/meshoptimizer
- SV_GroupIndex
- zeux/niagara
- The Stanford Bunny
- Nanite - A Deep Dive
- Billions of triangles in minutes - zeux.io
- clusterlod.h - meshoptimizer
- 2D Polyhedral Bounds of a Clipped, Perspective-Projected 3D Sphere (Michael Mara, Morgan McGuire)
- Approximate projected bounds - Arseny Kapoulkine
- clusterlod.h demo